Show Code
# import packages
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn# import packages
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn# define the dataset
X = np.array([[1, 2, 3], [7, 5, 3], [9, 6, 4]], dtype=float)
Y = np.array([10, 28, 40], dtype=float)
X = torch.tensor(X, dtype=torch.float32)
Y = torch.tensor(Y, dtype=torch.float32).reshape(-1, 1)# define the loss function
loss_fn = nn.MSELoss()def train(model, X, Y, loss_fn, optimizer, epochs=20):
losses = []
# reset the model parameters before training
model.apply(lambda m: m.reset_parameters() if hasattr(m, 'reset_parameters') else None)
for epoch in range(epochs):
# forward pass
predictions = model(X)
# calculate the loss
loss = loss_fn(predictions, Y)
# zero the gradients
optimizer.zero_grad()
# backward pass
loss.backward()
# INVESTIGATION: Access gradients here
# model[0] is the first Linear layer, model[2] is the second Linear layer
layer1_grad_norm = model[0].weight.grad.norm().item()
layer2_grad_norm = model[2].weight.grad.norm().item()
print(f"Epoch {epoch+1}/{epochs}, Loss: {loss.item():.4f}, Layer1 Grad Norm: {layer1_grad_norm:.4f}, Layer2 Grad Norm: {layer2_grad_norm:.4f}")
# update the weights
optimizer.step()
losses.append(loss.item())
print(f"Target: {Y.flatten()}\nPredictions: {predictions.detach().flatten()}")
return lossesBelow we will train two models with the same architecture but different optimizers (SGD and Adam) to see how they perform.
# Define model 1 with SGD optimizer
torch.manual_seed(42)
model_adam = nn.Sequential(
nn.Linear(in_features=3, out_features=5),
nn.ReLU(),
nn.Linear(in_features=5, out_features=1)
)
optimizer_adam = torch.optim.Adam(model_adam.parameters(), lr=0.1)
losses_adam = train(model_adam, X, Y, loss_fn, optimizer_adam, epochs=20)
torch.manual_seed(42)
model_sgd = nn.Sequential(
nn.Linear(in_features=3, out_features=5),
nn.ReLU(),
nn.Linear(in_features=5, out_features=1)
)
optimizer_sgd = torch.optim.SGD(model_sgd.parameters(), lr=0.001)
losses_sgd = train(model_sgd, X, Y, loss_fn, optimizer_sgd, epochs=20)
# plot the loss in two separate plots for better visibility
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(losses_sgd)
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("SGD Loss Curve")
plt.subplot(1, 2, 2)
plt.plot(losses_adam)
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("Adam Loss Curve")
plt.show()--- Epoch 1 Parameter Update Analysis ---
Param: 0.weight | Grad: 28.179852 | Effective LR: 0.100000
Param: 0.bias | Grad: 5.337008 | Effective LR: 0.100000
Param: 2.weight | Grad: 91.573013 | Effective LR: 0.100000
Param: 2.bias | Grad: 53.403225 | Effective LR: 0.100000
--- End of Epoch 1 Analysis ---
--- Epoch 2 Parameter Update Analysis ---
Param: 0.weight | Grad: 26.609163 | Effective LR: 0.067923
Param: 0.bias | Grad: 5.031293 | Effective LR: 0.373200
Param: 2.weight | Grad: 86.474670 | Effective LR: 0.021539
Param: 2.bias | Grad: 50.344177 | Effective LR: 0.059215
--- End of Epoch 2 Analysis ---
--- Epoch 3 Parameter Update Analysis ---
Param: 0.weight | Grad: 25.216082 | Effective LR: 0.048416
Param: 0.bias | Grad: 4.759209 | Effective LR: 0.266251
Param: 2.weight | Grad: 82.056374 | Effective LR: 0.015584
Param: 2.bias | Grad: 47.315224 | Effective LR: 0.043099
--- End of Epoch 3 Analysis ---
--- Epoch 4 Parameter Update Analysis ---
Param: 0.weight | Grad: 25.272682 | Effective LR: 0.038292
Param: 0.bias | Grad: 4.759966 | Effective LR: 0.210805
Param: 2.weight | Grad: 78.993141 | Effective LR: 0.012489
Param: 2.bias | Grad: 44.244827 | Effective LR: 0.036233
--- End of Epoch 4 Analysis ---
--- Epoch 5 Parameter Update Analysis ---
Param: 0.weight | Grad: 27.214708 | Effective LR: 0.031424
Param: 0.bias | Grad: 5.112923 | Effective LR: 0.173225
Param: 2.weight | Grad: 84.758713 | Effective LR: 0.010346
Param: 2.bias | Grad: 40.835655 | Effective LR: 0.032331
--- End of Epoch 5 Analysis ---
--- Epoch 6 Parameter Update Analysis ---
Param: 0.weight | Grad: 28.582296 | Effective LR: 0.026601
Param: 0.bias | Grad: 5.350596 | Effective LR: 0.146863
Param: 2.weight | Grad: 89.331360 | Effective LR: 0.008796
Param: 2.bias | Grad: 36.826920 | Effective LR: 0.029848
--- End of Epoch 6 Analysis ---
--- Epoch 7 Parameter Update Analysis ---
Param: 0.weight | Grad: 28.628771 | Effective LR: 0.023218
Param: 0.bias | Grad: 5.331194 | Effective LR: 0.128426
Param: 2.weight | Grad: 89.708817 | Effective LR: 0.007692
Param: 2.bias | Grad: 32.211647 | Effective LR: 0.028206
--- End of Epoch 7 Analysis ---
--- Epoch 8 Parameter Update Analysis ---
Param: 0.weight | Grad: 27.147367 | Effective LR: 0.020860
Param: 0.bias | Grad: 5.014503 | Effective LR: 0.115639
Param: 2.weight | Grad: 85.230881 | Effective LR: 0.006916
Param: 2.bias | Grad: 26.982700 | Effective LR: 0.027121
--- End of Epoch 8 Analysis ---
--- Epoch 9 Parameter Update Analysis ---
Param: 0.weight | Grad: 23.937450 | Effective LR: 0.019258
Param: 0.bias | Grad: 4.361578 | Effective LR: 0.107040
Param: 2.weight | Grad: 75.257599 | Effective LR: 0.006386
Param: 2.bias | Grad: 21.147682 | Effective LR: 0.026436
--- End of Epoch 9 Analysis ---
--- Epoch 10 Parameter Update Analysis ---
Param: 0.weight | Grad: 18.835934 | Effective LR: 0.018239
Param: 0.bias | Grad: 3.340894 | Effective LR: 0.101690
Param: 2.weight | Grad: 59.268848 | Effective LR: 0.006049
Param: 2.bias | Grad: 14.744608 | Effective LR: 0.026045
--- End of Epoch 10 Analysis ---
--- Epoch 11 Parameter Update Analysis ---
Param: 0.weight | Grad: 11.782027 | Effective LR: 0.017685
Param: 0.bias | Grad: 1.941030 | Effective LR: 0.098924
Param: 2.weight | Grad: 37.069870 | Effective LR: 0.005866
Param: 2.bias | Grad: 7.870871 | Effective LR: 0.025867
--- End of Epoch 11 Analysis ---
--- Epoch 12 Parameter Update Analysis ---
Param: 0.weight | Grad: 2.942373 | Effective LR: 0.017485
Param: 0.bias | Grad: 0.195136 | Effective LR: 0.098073
Param: 2.weight | Grad: 9.188245 | Effective LR: 0.005801
Param: 2.bias | Grad: 0.734004 | Effective LR: 0.025827
--- End of Epoch 12 Analysis ---
--- Epoch 13 Parameter Update Analysis ---
Param: 0.weight | Grad: 7.086957 | Effective LR: 0.017479
Param: 0.bias | Grad: 1.779598 | Effective LR: 0.098113
Param: 2.weight | Grad: 22.486273 | Effective LR: 0.005800
Param: 2.bias | Grad: 6.276864 | Effective LR: 0.025839
--- End of Epoch 13 Analysis ---
--- Epoch 14 Parameter Update Analysis ---
Param: 0.weight | Grad: 17.093729 | Effective LR: 0.017419
Param: 0.bias | Grad: 3.745628 | Effective LR: 0.097421
Param: 2.weight | Grad: 54.112232 | Effective LR: 0.005778
Param: 2.bias | Grad: 12.550220 | Effective LR: 0.025818
--- End of Epoch 14 Analysis ---
--- Epoch 15 Parameter Update Analysis ---
Param: 0.weight | Grad: 25.410807 | Effective LR: 0.017033
Param: 0.bias | Grad: 5.376987 | Effective LR: 0.094376
Param: 2.weight | Grad: 80.409866 | Effective LR: 0.005645
Param: 2.bias | Grad: 17.376568 | Effective LR: 0.025696
--- End of Epoch 15 Analysis ---
--- Epoch 16 Parameter Update Analysis ---
Param: 0.weight | Grad: 30.643002 | Effective LR: 0.016251
Param: 0.bias | Grad: 6.401639 | Effective LR: 0.088870
Param: 2.weight | Grad: 96.960800 | Effective LR: 0.005377
Param: 2.bias | Grad: 20.270622 | Effective LR: 0.025457
--- End of Epoch 16 Analysis ---
--- Epoch 17 Parameter Update Analysis ---
Param: 0.weight | Grad: 32.325710 | Effective LR: 0.015280
Param: 0.bias | Grad: 6.729838 | Effective LR: 0.082484
Param: 2.weight | Grad: 102.289238 | Effective LR: 0.005047
Param: 2.bias | Grad: 21.181379 | Effective LR: 0.025136
--- End of Epoch 17 Analysis ---
--- Epoch 18 Parameter Update Analysis ---
Param: 0.weight | Grad: 30.855795 | Effective LR: 0.014381
Param: 0.bias | Grad: 6.440007 | Effective LR: 0.076814
Param: 2.weight | Grad: 97.644791 | Effective LR: 0.004743
Param: 2.bias | Grad: 20.387068 | Effective LR: 0.024800
--- End of Epoch 18 Analysis ---
--- Epoch 19 Parameter Update Analysis ---
Param: 0.weight | Grad: 27.044250 | Effective LR: 0.013687
Param: 0.bias | Grad: 5.691142 | Effective LR: 0.072539
Param: 2.weight | Grad: 85.590202 | Effective LR: 0.004510
Param: 2.bias | Grad: 18.291176 | Effective LR: 0.024501
--- End of Epoch 19 Analysis ---
--- Epoch 20 Parameter Update Analysis ---
Param: 0.weight | Grad: 21.773497 | Effective LR: 0.013220
Param: 0.bias | Grad: 4.655953 | Effective LR: 0.069665
Param: 2.weight | Grad: 68.917130 | Effective LR: 0.004353
Param: 2.bias | Grad: 15.301039 | Effective LR: 0.024270
--- End of Epoch 20 Analysis ---
Target: tensor([10., 28., 40.])
Predictions: tensor([15.6741, 38.0796, 47.1978])
--- Epoch 1 Parameter Update Analysis ---
Param: 0.weight | Grad: 28.179852 | Effective LR: 0.001000
Param: 0.bias | Grad: 5.337008 | Effective LR: 0.001000
Param: 2.weight | Grad: 91.573013 | Effective LR: 0.001000
Param: 2.bias | Grad: 53.403225 | Effective LR: 0.001000
--- End of Epoch 1 Analysis ---
--- Epoch 2 Parameter Update Analysis ---
Param: 0.weight | Grad: 21.968004 | Effective LR: 0.001000
Param: 0.bias | Grad: 4.155200 | Effective LR: 0.001000
Param: 2.weight | Grad: 82.182693 | Effective LR: 0.001000
Param: 2.bias | Grad: 49.138721 | Effective LR: 0.001000
--- End of Epoch 2 Analysis ---
--- Epoch 3 Parameter Update Analysis ---
Param: 0.weight | Grad: 38.463688 | Effective LR: 0.001000
Param: 0.bias | Grad: 7.269441 | Effective LR: 0.001000
Param: 2.weight | Grad: 90.333389 | Effective LR: 0.001000
Param: 2.bias | Grad: 44.147633 | Effective LR: 0.001000
--- End of Epoch 3 Analysis ---
--- Epoch 4 Parameter Update Analysis ---
Param: 0.weight | Grad: 47.922321 | Effective LR: 0.001000
Param: 0.bias | Grad: 9.047905 | Effective LR: 0.001000
Param: 2.weight | Grad: 96.407921 | Effective LR: 0.001000
Param: 2.bias | Grad: 35.482613 | Effective LR: 0.001000
--- End of Epoch 4 Analysis ---
--- Epoch 5 Parameter Update Analysis ---
Param: 0.weight | Grad: 41.170727 | Effective LR: 0.001000
Param: 0.bias | Grad: 7.752571 | Effective LR: 0.001000
Param: 2.weight | Grad: 78.505943 | Effective LR: 0.001000
Param: 2.bias | Grad: 22.061743 | Effective LR: 0.001000
--- End of Epoch 5 Analysis ---
--- Epoch 6 Parameter Update Analysis ---
Param: 0.weight | Grad: 18.281893 | Effective LR: 0.001000
Param: 0.bias | Grad: 3.400041 | Effective LR: 0.001000
Param: 2.weight | Grad: 34.170944 | Effective LR: 0.001000
Param: 2.bias | Grad: 7.908741 | Effective LR: 0.001000
--- End of Epoch 6 Analysis ---
--- Epoch 7 Parameter Update Analysis ---
Param: 0.weight | Grad: 2.448281 | Effective LR: 0.001000
Param: 0.bias | Grad: 0.391544 | Effective LR: 0.001000
Param: 2.weight | Grad: 4.454276 | Effective LR: 0.001000
Param: 2.bias | Grad: 0.843699 | Effective LR: 0.001000
--- End of Epoch 7 Analysis ---
--- Epoch 8 Parameter Update Analysis ---
Param: 0.weight | Grad: 0.165727 | Effective LR: 0.001000
Param: 0.bias | Grad: 0.055054 | Effective LR: 0.001000
Param: 2.weight | Grad: 0.076006 | Effective LR: 0.001000
Param: 2.bias | Grad: 0.117503 | Effective LR: 0.001000
--- End of Epoch 8 Analysis ---
--- Epoch 9 Parameter Update Analysis ---
Param: 0.weight | Grad: 0.183319 | Effective LR: 0.001000
Param: 0.bias | Grad: 0.062646 | Effective LR: 0.001000
Param: 2.weight | Grad: 0.099122 | Effective LR: 0.001000
Param: 2.bias | Grad: 0.133685 | Effective LR: 0.001000
--- End of Epoch 9 Analysis ---
--- Epoch 10 Parameter Update Analysis ---
Param: 0.weight | Grad: 0.181884 | Effective LR: 0.001000
Param: 0.bias | Grad: 0.063762 | Effective LR: 0.001000
Param: 2.weight | Grad: 0.098241 | Effective LR: 0.001000
Param: 2.bias | Grad: 0.136063 | Effective LR: 0.001000
--- End of Epoch 10 Analysis ---
--- Epoch 11 Parameter Update Analysis ---
Param: 0.weight | Grad: 0.180448 | Effective LR: 0.001000
Param: 0.bias | Grad: 0.064855 | Effective LR: 0.001000
Param: 2.weight | Grad: 0.097346 | Effective LR: 0.001000
Param: 2.bias | Grad: 0.138392 | Effective LR: 0.001000
--- End of Epoch 11 Analysis ---
--- Epoch 12 Parameter Update Analysis ---
Param: 0.weight | Grad: 0.179050 | Effective LR: 0.001000
Param: 0.bias | Grad: 0.065938 | Effective LR: 0.001000
Param: 2.weight | Grad: 0.096485 | Effective LR: 0.001000
Param: 2.bias | Grad: 0.140697 | Effective LR: 0.001000
--- End of Epoch 12 Analysis ---
--- Epoch 13 Parameter Update Analysis ---
Param: 0.weight | Grad: 0.177646 | Effective LR: 0.001000
Param: 0.bias | Grad: 0.066997 | Effective LR: 0.001000
Param: 2.weight | Grad: 0.095607 | Effective LR: 0.001000
Param: 2.bias | Grad: 0.142955 | Effective LR: 0.001000
--- End of Epoch 13 Analysis ---
--- Epoch 14 Parameter Update Analysis ---
Param: 0.weight | Grad: 0.176284 | Effective LR: 0.001000
Param: 0.bias | Grad: 0.068048 | Effective LR: 0.001000
Param: 2.weight | Grad: 0.094771 | Effective LR: 0.001000
Param: 2.bias | Grad: 0.145193 | Effective LR: 0.001000
--- End of Epoch 14 Analysis ---
--- Epoch 15 Parameter Update Analysis ---
Param: 0.weight | Grad: 0.174925 | Effective LR: 0.001000
Param: 0.bias | Grad: 0.069078 | Effective LR: 0.001000
Param: 2.weight | Grad: 0.093926 | Effective LR: 0.001000
Param: 2.bias | Grad: 0.147387 | Effective LR: 0.001000
--- End of Epoch 15 Analysis ---
--- Epoch 16 Parameter Update Analysis ---
Param: 0.weight | Grad: 0.173606 | Effective LR: 0.001000
Param: 0.bias | Grad: 0.070100 | Effective LR: 0.001000
Param: 2.weight | Grad: 0.093121 | Effective LR: 0.001000
Param: 2.bias | Grad: 0.149563 | Effective LR: 0.001000
--- End of Epoch 16 Analysis ---
--- Epoch 17 Parameter Update Analysis ---
Param: 0.weight | Grad: 0.172275 | Effective LR: 0.001000
Param: 0.bias | Grad: 0.071097 | Effective LR: 0.001000
Param: 2.weight | Grad: 0.092286 | Effective LR: 0.001000
Param: 2.bias | Grad: 0.151687 | Effective LR: 0.001000
--- End of Epoch 17 Analysis ---
--- Epoch 18 Parameter Update Analysis ---
Param: 0.weight | Grad: 0.170988 | Effective LR: 0.001000
Param: 0.bias | Grad: 0.072088 | Effective LR: 0.001000
Param: 2.weight | Grad: 0.091500 | Effective LR: 0.001000
Param: 2.bias | Grad: 0.153798 | Effective LR: 0.001000
--- End of Epoch 18 Analysis ---
--- Epoch 19 Parameter Update Analysis ---
Param: 0.weight | Grad: 0.169705 | Effective LR: 0.001000
Param: 0.bias | Grad: 0.073060 | Effective LR: 0.001000
Param: 2.weight | Grad: 0.090706 | Effective LR: 0.001000
Param: 2.bias | Grad: 0.155868 | Effective LR: 0.001000
--- End of Epoch 19 Analysis ---
--- Epoch 20 Parameter Update Analysis ---
Param: 0.weight | Grad: 0.168457 | Effective LR: 0.001000
Param: 0.bias | Grad: 0.074024 | Effective LR: 0.001000
Param: 2.weight | Grad: 0.089945 | Effective LR: 0.001000
Param: 2.bias | Grad: 0.157919 | Effective LR: 0.001000
--- End of Epoch 20 Analysis ---
Target: tensor([10., 28., 40.])
Predictions: tensor([ 9.6553, 30.3903, 38.1913])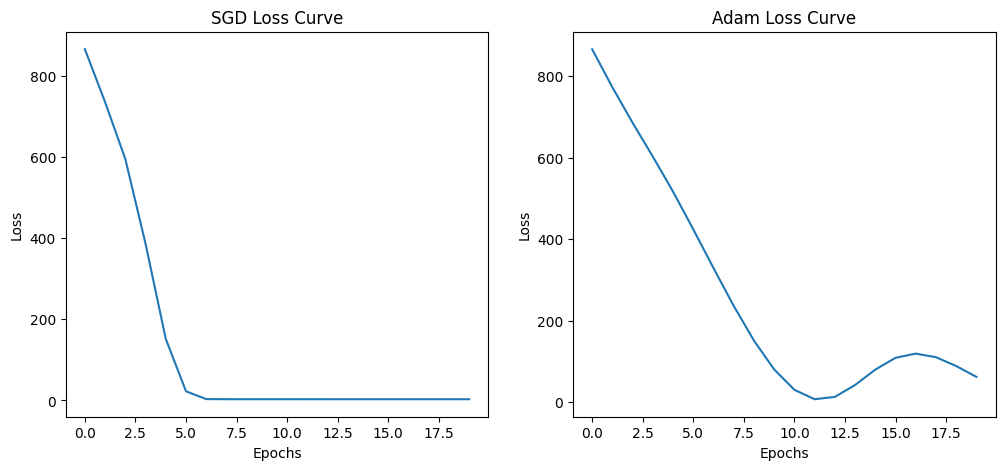
Notice that using the SGD optimizer led to a loss of near 0 on epocch 15, while the Adam optimizer on the same epoch is still around 800 loss, which is a significant difference. This is unexpected since Adam is often considered a more advanced optimizer than SGD, and it should typically converge faster.
What Adam does? It computes adaptive learning rates for each parameter by keeping track of the first and second moments of the gradients. Meaning that the learning rate for each parameter is adjusted based on the historical gradients. For that we need to keep track of the first moment \(m_t\) (the mean of the gradients) and the second moment \(v_t\) (the variance of the gradients).
Adam update equation is: \[\begin{aligned} m_t &= \beta_1 m_{t-1} + (1 - \beta_1) g_t \\ v_t &= \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 \\ \hat{m}_t &= \frac{m_t}{1 - \beta_1^t} \\ \hat{v}_t &= \frac{v_t}{1 - \beta_2^t} \\ \theta_t &= \theta_{t-1} - \alpha \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon} \end{aligned}\]
where: - \(g_t\) is the gradient at time step \(t\) - \(\beta_1\) and \(\beta_2\) are the decay rates for the moving averages (commonly set to 0.9 and 0.999 respectively) - \(\alpha\) is the learning rate
What does the above means??
It means that some parameters: - get large gradients - others get tiny gradients
Adam will adjust the learning rate for each parameter based on the historical gradients.
def train(model, X, Y, loss_fn, optimizer, epochs=20):
losses = []
# reset the model parameters before training
model.apply(lambda m: m.reset_parameters() if hasattr(m, 'reset_parameters') else None)
for epoch in range(epochs):
# forward pass
predictions = model(X)
# calculate the loss
loss = loss_fn(predictions, Y)
# zero the gradients
optimizer.zero_grad()
# backward pass
loss.backward()
print(f"--- Epoch {epoch+1} Parameter Update Analysis ---")
for name, param in model.named_parameters():
if param.grad is not None:
# 1. Calculate the raw gradient mean
grad_avg = param.grad.abs().mean().item()
# 2. Identify the optimizer type and calculate effective LR
if isinstance(optimizer, torch.optim.SGD):
# For SGD, effective LR is always the fixed global LR
eff_lr = optimizer.param_groups[0]['lr']
elif isinstance(optimizer, torch.optim.Adam):
# For Adam, we look into the optimizer's internal state (buffers)
state = optimizer.state[param]
if 'exp_avg_sq' in state:
v_t = state['exp_avg_sq'].mean().item()
eps = optimizer.param_groups[0]['eps']
global_lr = optimizer.param_groups[0]['lr']
# Effective LR = global_lr / (sqrt(v_t) + eps)
eff_lr = global_lr / (np.sqrt(v_t) + eps)
else:
eff_lr = optimizer.param_groups[0]['lr'] # First step
print(f"Param: {name:15} | Grad: {grad_avg:.6f} | Effective LR: {eff_lr:.6f}")
print(f"--- End of Epoch {epoch+1} Analysis ---\n")
# update the weights
optimizer.step()
losses.append(loss.item())
print(f"Target: {Y.flatten()}\nPredictions: {predictions.detach().flatten()}")
return lossesWe will implement a custom optimizer class then use it in the training to get a better understanding of how optimizers work and how updates are calculated.
self.param_groups contains this:
[
{
"params": [
Parameter(tensor_layer1_weights),
Parameter(tensor_layer1_bias),
Parameter(tensor_layer2_weights),
Parameter(tensor_layer2_bias)
],
"lr": 0.01,
"momentum": 0.9,
"weight_decay": 0.0001
}
]class MyCustomSGD(torch.optim.Optimizer): # 1. Inherit from torch.optim.Optimizer
def __init__(self, params, lr=0.01):
defaults = dict(lr=lr) # PyTorch takes lr and puts it into the param_groups list.
super().__init__(params, defaults)
def step(self):
"""Performs a single optimization step."""
for group in self.param_groups:
lr = group['lr']
for p in group['params']:
if p.grad is None:
continue
# IMPORTANT: do updates without tracking gradients
with torch.no_grad():
p.add_(p.grad, alpha=-lr) # equivalent to p = p - lr * p.gradNow let’s modify the training loop to print the magnitude of the updates for each parameter at each epoch, and see the gradients as well. This will help us understand how the optimizer is updating the parameters and how the gradients are evolving during training.
def train(model, X, Y, loss_fn, optimizer, epochs=20):
losses = []
# reset the model parameters before training
model.apply(lambda m: m.reset_parameters() if hasattr(m, 'reset_parameters') else None)
for epoch in range(epochs):
# forward pass
predictions = model(X)
# calculate the loss
loss = loss_fn(predictions, Y)
# zero the gradients
optimizer.zero_grad()
# backward pass
loss.backward()
# ACCESS THE CURRENT LEARNING RATE
current_lr = optimizer.param_groups[0]['lr']
# INVESTIGATION: Access gradients here
layer1_grad_norm = model[0].weight.grad.norm().item()
layer2_grad_norm = model[2].weight.grad.norm().item()
print(f"Epoch {epoch+1}/{epochs}, Loss: {loss.item():.4f}, LR: {current_lr:.6f}, Layer1 Grad Norm: {layer1_grad_norm:.4f}, Layer2 Grad Norm: {layer2_grad_norm:.4f}")
# update the weights
optimizer.step()
losses.append(loss.item())
print(f"Target: {Y.flatten()}\nPredictions: {predictions.detach().flatten()}")
return lossestorch.manual_seed(22)
optimizer_sgd = MyCustomSGD(model_sgd.parameters(), lr=0.001)
losses_sgd = train(model_sgd, X, Y, loss_fn, optimizer_sgd, epochs=20)Epoch 1/20, Loss: 766.2837, LR: 0.001000, Layer1 Grad Norm: 72.0186, Layer2 Grad Norm: 405.2615
Epoch 2/20, Loss: 594.2346, LR: 0.001000, Layer1 Grad Norm: 223.7336, Layer2 Grad Norm: 381.0798
Epoch 3/20, Loss: 383.6776, LR: 0.001000, Layer1 Grad Norm: 307.5072, Layer2 Grad Norm: 381.4230
Epoch 4/20, Loss: 153.8463, LR: 0.001000, Layer1 Grad Norm: 274.3780, Layer2 Grad Norm: 305.6354
Epoch 5/20, Loss: 24.6462, LR: 0.001000, Layer1 Grad Norm: 127.5381, Layer2 Grad Norm: 136.5847
Epoch 6/20, Loss: 3.8731, LR: 0.001000, Layer1 Grad Norm: 19.6383, Layer2 Grad Norm: 19.9870
Epoch 7/20, Loss: 3.4603, LR: 0.001000, Layer1 Grad Norm: 3.4835, Layer2 Grad Norm: 0.4799
Epoch 8/20, Loss: 3.4455, LR: 0.001000, Layer1 Grad Norm: 3.3365, Layer2 Grad Norm: 0.3390
Epoch 9/20, Loss: 3.4313, LR: 0.001000, Layer1 Grad Norm: 3.2913, Layer2 Grad Norm: 0.3365
Epoch 10/20, Loss: 3.4175, LR: 0.001000, Layer1 Grad Norm: 3.2475, Layer2 Grad Norm: 0.3310
Epoch 11/20, Loss: 3.4041, LR: 0.001000, Layer1 Grad Norm: 3.2044, Layer2 Grad Norm: 0.3257
Epoch 12/20, Loss: 3.3910, LR: 0.001000, Layer1 Grad Norm: 3.1620, Layer2 Grad Norm: 0.3205
Epoch 13/20, Loss: 3.3782, LR: 0.001000, Layer1 Grad Norm: 3.1201, Layer2 Grad Norm: 0.3155
Epoch 14/20, Loss: 3.3657, LR: 0.001000, Layer1 Grad Norm: 3.0790, Layer2 Grad Norm: 0.3107
Epoch 15/20, Loss: 3.3535, LR: 0.001000, Layer1 Grad Norm: 3.0384, Layer2 Grad Norm: 0.3059
Epoch 16/20, Loss: 3.3416, LR: 0.001000, Layer1 Grad Norm: 2.9985, Layer2 Grad Norm: 0.3013
Epoch 17/20, Loss: 3.3300, LR: 0.001000, Layer1 Grad Norm: 2.9592, Layer2 Grad Norm: 0.2969
Epoch 18/20, Loss: 3.3186, LR: 0.001000, Layer1 Grad Norm: 2.9205, Layer2 Grad Norm: 0.2926
Epoch 19/20, Loss: 3.3076, LR: 0.001000, Layer1 Grad Norm: 2.8824, Layer2 Grad Norm: 0.2885
Epoch 20/20, Loss: 3.2968, LR: 0.001000, Layer1 Grad Norm: 2.8449, Layer2 Grad Norm: 0.2844
Target: tensor([10., 28., 40.])
Predictions: tensor([10.9615, 30.2130, 37.9829])The m in the code below is the first moment (the mean of the gradients), it is an exponential moving average of the gradients that smooths gradients over time thus reducing noise.
Intuition: - Instead of using raw gradient: “Where should I go on average?”
The v is the second moment (the variance of the gradients), it tracks how big the gradients are on average.
class MyCustomAdam(torch.optim.Optimizer):
def __init__(self, params, lr=0.001, betas=(0.9, 0.999), eps=1e-8):
defaults = dict(lr=lr, betas=betas, eps=eps)
super().__init__(params, defaults) # pass the defaults to the parent class so it can handle param_groups and state management
def step(self):
for group in self.param_groups:
lr = group['lr']
beta1, beta2 = group['betas']
eps = group['eps']
for p in group['params']:
if p.grad is None:
continue
grad = p.grad
# get the state for this parameter (Each parameter has its own state dict)
state = self.state[p]
# State initialization
if len(state) == 0:
state['step'] = 0
state['m'] = torch.zeros_like(p) # momentum (mean of gradients)
state['v'] = torch.zeros_like(p) # variance (mean of squared gradients)
# above we initialize m and v to zeros, meaning we start with no history
m, v = state['m'], state['v']
state['step'] += 1
# ----- 1. Update biased first moment estimate (momentum) -----
m.mul_(beta1).add_(grad, alpha=1 - beta1) # m = beta1 * m + (1 - beta1) * grad
# ----- 2. Update biased second moment estimate (variance) -----
v.mul_(beta2).addcmul_(grad, grad, value=1 - beta2) # v = beta2 * v + (1 - beta2) * (grad * grad)
# ----- 3. Compute bias-corrected first and second moment estimates -----
m_hat = m / (1 - beta1 ** state['step']) # bias-corrected momentum
v_hat = v / (1 - beta2 ** state['step']) # bias-corrected variance
# print evective learning rate for debugging
effective_lr = lr / (v_hat.sqrt() + eps)
if state['step'] % 10 == 0: # print every 10 steps
print(f"Step {state['step']}: Effective LR: {effective_lr.mean().item():.6f}")
# ----- 4. Update parameters -----
with torch.no_grad():
p.addcdiv_(m_hat, v_hat.sqrt().add(eps), value=-lr) # p = p - lr * m_hat / (sqrt(v_hat) + eps)
torch.manual_seed(23)
model_adam = nn.Sequential(
nn.Linear(in_features=3, out_features=5),
nn.ReLU(),
nn.Linear(in_features=5, out_features=1)
)
optimizer_adam = MyCustomAdam(model_adam.parameters(), lr=0.1)
losses_adam = train(model_adam, X, Y, loss_fn, optimizer_adam, epochs=50)Epoch 1/50, Loss: 1017.2559, LR: 0.100000, Layer1 Grad Norm: 270.9026, Layer2 Grad Norm: 442.3324
Epoch 2/50, Loss: 907.9037, LR: 0.100000, Layer1 Grad Norm: 140.3252, Layer2 Grad Norm: 293.4350
Epoch 3/50, Loss: 850.2083, LR: 0.100000, Layer1 Grad Norm: 69.6186, Layer2 Grad Norm: 179.2594
Epoch 4/50, Loss: 824.6230, LR: 0.100000, Layer1 Grad Norm: 17.5018, Layer2 Grad Norm: 96.3344
Epoch 5/50, Loss: 814.5988, LR: 0.100000, Layer1 Grad Norm: 23.9574, Layer2 Grad Norm: 29.5090
Epoch 6/50, Loss: 810.9821, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 7/50, Loss: 805.8967, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 8/50, Loss: 800.8347, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 9/50, Loss: 795.7956, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 10/50, Loss: 790.7792, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Step 10: Effective LR: 4000000.000000
Step 10: Effective LR: 4000000.000000
Step 10: Effective LR: 4000000.000000
Step 10: Effective LR: 0.001910
Epoch 11/50, Loss: 785.7858, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 12/50, Loss: 780.8155, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 13/50, Loss: 775.8685, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 14/50, Loss: 770.9448, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 15/50, Loss: 766.0445, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 16/50, Loss: 761.1680, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 17/50, Loss: 756.3155, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 18/50, Loss: 751.4871, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 19/50, Loss: 746.6830, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 20/50, Loss: 741.9035, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Step 20: Effective LR: 4000000.000000
Step 20: Effective LR: 4000000.000000
Step 20: Effective LR: 4000000.000000
Step 20: Effective LR: 0.001964
Epoch 21/50, Loss: 737.1484, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 22/50, Loss: 732.4184, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 23/50, Loss: 727.7132, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 24/50, Loss: 723.0332, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 25/50, Loss: 718.3784, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 26/50, Loss: 713.7490, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 27/50, Loss: 709.1452, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 28/50, Loss: 704.5669, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 29/50, Loss: 700.0143, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 30/50, Loss: 695.4876, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Step 30: Effective LR: 4000000.000000
Step 30: Effective LR: 4000000.000000
Step 30: Effective LR: 4000000.000000
Step 30: Effective LR: 0.002008
Epoch 31/50, Loss: 690.9866, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 32/50, Loss: 686.5117, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 33/50, Loss: 682.0627, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 34/50, Loss: 677.6398, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 35/50, Loss: 673.2429, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 36/50, Loss: 668.8723, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 37/50, Loss: 664.5276, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 38/50, Loss: 660.2092, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 39/50, Loss: 655.9169, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 40/50, Loss: 651.6509, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Step 40: Effective LR: 4000000.000000
Step 40: Effective LR: 4000000.000000
Step 40: Effective LR: 4000000.000000
Step 40: Effective LR: 0.002051
Epoch 41/50, Loss: 647.4111, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 42/50, Loss: 643.1973, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 43/50, Loss: 639.0098, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 44/50, Loss: 634.8482, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 45/50, Loss: 630.7129, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 46/50, Loss: 626.6037, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 47/50, Loss: 622.5204, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 48/50, Loss: 618.4632, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 49/50, Loss: 614.4319, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Epoch 50/50, Loss: 610.4267, LR: 0.100000, Layer1 Grad Norm: 0.0000, Layer2 Grad Norm: 0.0000
Step 50: Effective LR: 4000000.000000
Step 50: Effective LR: 4000000.000000
Step 50: Effective LR: 4000000.000000
Step 50: Effective LR: 0.002094
Target: tensor([10., 28., 40.])
Predictions: tensor([4.5891, 4.5891, 4.5891])The above indicate that are 3 parameters in the model are dead, this is because the gradients are zero for those parameters. Now let’s see how chosing LeakyReLU instead of ReLU can help with this issue.
torch.manual_seed(23)
model_adam = nn.Sequential(
nn.Linear(in_features=3, out_features=5),
nn.LeakyReLU(0.01),
nn.Linear(in_features=5, out_features=1)
)
optimizer_adam = MyCustomAdam(model_adam.parameters(), lr=0.1)
losses_adam = train(model_adam, X, Y, loss_fn, optimizer_adam, epochs=50)Epoch 1/50, Loss: 1016.1404, LR: 0.100000, Layer1 Grad Norm: 270.7620, Layer2 Grad Norm: 442.0994
Epoch 2/50, Loss: 905.7834, LR: 0.100000, Layer1 Grad Norm: 140.2095, Layer2 Grad Norm: 293.1149
Epoch 3/50, Loss: 846.8618, LR: 0.100000, Layer1 Grad Norm: 69.5649, Layer2 Grad Norm: 178.9893
Epoch 4/50, Loss: 819.7873, LR: 0.100000, Layer1 Grad Norm: 17.8728, Layer2 Grad Norm: 96.2938
Epoch 5/50, Loss: 808.0178, LR: 0.100000, Layer1 Grad Norm: 24.2593, Layer2 Grad Norm: 30.4131
Epoch 6/50, Loss: 802.3870, LR: 0.100000, Layer1 Grad Norm: 5.1779, Layer2 Grad Norm: 9.0167
Epoch 7/50, Loss: 795.0480, LR: 0.100000, Layer1 Grad Norm: 5.8958, Layer2 Grad Norm: 10.2844
Epoch 8/50, Loss: 787.4252, LR: 0.100000, Layer1 Grad Norm: 6.6091, Layer2 Grad Norm: 11.5377
Epoch 9/50, Loss: 779.4858, LR: 0.100000, Layer1 Grad Norm: 7.3128, Layer2 Grad Norm: 12.7720
Epoch 10/50, Loss: 771.2065, LR: 0.100000, Layer1 Grad Norm: 8.0051, Layer2 Grad Norm: 13.9862
Step 10: Effective LR: 0.025156
Step 10: Effective LR: 0.122478
Step 10: Effective LR: 0.008564
Step 10: Effective LR: 0.001920
Epoch 11/50, Loss: 762.5701, LR: 0.100000, Layer1 Grad Norm: 8.6858, Layer2 Grad Norm: 15.1807
Epoch 12/50, Loss: 753.5645, LR: 0.100000, Layer1 Grad Norm: 9.3552, Layer2 Grad Norm: 16.3559
Epoch 13/50, Loss: 744.1801, LR: 0.100000, Layer1 Grad Norm: 10.0138, Layer2 Grad Norm: 17.5125
Epoch 14/50, Loss: 734.4108, LR: 0.100000, Layer1 Grad Norm: 10.6618, Layer2 Grad Norm: 18.6508
Epoch 15/50, Loss: 724.2525, LR: 0.100000, Layer1 Grad Norm: 11.2996, Layer2 Grad Norm: 19.7709
Epoch 16/50, Loss: 713.7029, LR: 0.100000, Layer1 Grad Norm: 11.9271, Layer2 Grad Norm: 20.8724
Epoch 17/50, Loss: 702.7619, LR: 0.100000, Layer1 Grad Norm: 12.5442, Layer2 Grad Norm: 21.9550
Epoch 18/50, Loss: 691.4307, LR: 0.100000, Layer1 Grad Norm: 13.1508, Layer2 Grad Norm: 23.0178
Epoch 19/50, Loss: 679.7120, LR: 0.100000, Layer1 Grad Norm: 13.7462, Layer2 Grad Norm: 24.0599
Epoch 20/50, Loss: 667.6104, LR: 0.100000, Layer1 Grad Norm: 14.3300, Layer2 Grad Norm: 25.0800
Step 20: Effective LR: 0.015959
Step 20: Effective LR: 0.077936
Step 20: Effective LR: 0.006381
Step 20: Effective LR: 0.002000
Epoch 21/50, Loss: 655.1313, LR: 0.100000, Layer1 Grad Norm: 14.9014, Layer2 Grad Norm: 26.0766
Epoch 22/50, Loss: 642.2822, LR: 0.100000, Layer1 Grad Norm: 15.4596, Layer2 Grad Norm: 27.0483
Epoch 23/50, Loss: 629.0714, LR: 0.100000, Layer1 Grad Norm: 16.0036, Layer2 Grad Norm: 27.9932
Epoch 24/50, Loss: 615.5090, LR: 0.100000, Layer1 Grad Norm: 16.5324, Layer2 Grad Norm: 28.9095
Epoch 25/50, Loss: 601.6064, LR: 0.100000, Layer1 Grad Norm: 17.0448, Layer2 Grad Norm: 29.7952
Epoch 26/50, Loss: 587.3765, LR: 0.100000, Layer1 Grad Norm: 17.5396, Layer2 Grad Norm: 30.6482
Epoch 27/50, Loss: 572.8334, LR: 0.100000, Layer1 Grad Norm: 18.0155, Layer2 Grad Norm: 31.4664
Epoch 28/50, Loss: 557.9931, LR: 0.100000, Layer1 Grad Norm: 18.4713, Layer2 Grad Norm: 32.2473
Epoch 29/50, Loss: 542.8727, LR: 0.100000, Layer1 Grad Norm: 18.9055, Layer2 Grad Norm: 32.9888
Epoch 30/50, Loss: 527.4908, LR: 0.100000, Layer1 Grad Norm: 19.3168, Layer2 Grad Norm: 33.6885
Step 30: Effective LR: 0.013036
Step 30: Effective LR: 0.063862
Step 30: Effective LR: 0.005822
Step 30: Effective LR: 0.002094
Epoch 31/50, Loss: 511.8677, LR: 0.100000, Layer1 Grad Norm: 19.7036, Layer2 Grad Norm: 34.3439
Epoch 32/50, Loss: 496.0249, LR: 0.100000, Layer1 Grad Norm: 20.0647, Layer2 Grad Norm: 34.9527
Epoch 33/50, Loss: 479.9857, LR: 0.100000, Layer1 Grad Norm: 20.3984, Layer2 Grad Norm: 35.5123
Epoch 34/50, Loss: 463.7745, LR: 0.100000, Layer1 Grad Norm: 20.7033, Layer2 Grad Norm: 36.0204
Epoch 35/50, Loss: 447.4176, LR: 0.100000, Layer1 Grad Norm: 20.9780, Layer2 Grad Norm: 36.4746
Epoch 36/50, Loss: 430.9423, LR: 0.100000, Layer1 Grad Norm: 21.2211, Layer2 Grad Norm: 36.8724
Epoch 37/50, Loss: 414.3775, LR: 0.100000, Layer1 Grad Norm: 21.4311, Layer2 Grad Norm: 37.2116
Epoch 38/50, Loss: 397.7533, LR: 0.100000, Layer1 Grad Norm: 21.6068, Layer2 Grad Norm: 37.4899
Epoch 39/50, Loss: 381.1011, LR: 0.100000, Layer1 Grad Norm: 21.7467, Layer2 Grad Norm: 37.7051
Epoch 40/50, Loss: 364.4536, LR: 0.100000, Layer1 Grad Norm: 21.8497, Layer2 Grad Norm: 37.8552
Step 40: Effective LR: 0.011982
Step 40: Effective LR: 0.058911
Step 40: Effective LR: 0.005738
Step 40: Effective LR: 0.002217
Epoch 41/50, Loss: 347.8445, LR: 0.100000, Layer1 Grad Norm: 21.9145, Layer2 Grad Norm: 37.9382
Epoch 42/50, Loss: 331.3083, LR: 0.100000, Layer1 Grad Norm: 21.9401, Layer2 Grad Norm: 37.9523
Epoch 43/50, Loss: 314.8808, LR: 0.100000, Layer1 Grad Norm: 21.9254, Layer2 Grad Norm: 37.8957
Epoch 44/50, Loss: 298.5981, LR: 0.100000, Layer1 Grad Norm: 21.8695, Layer2 Grad Norm: 37.7671
Epoch 45/50, Loss: 282.4971, LR: 0.100000, Layer1 Grad Norm: 21.7716, Layer2 Grad Norm: 37.5650
Epoch 46/50, Loss: 266.6150, LR: 0.100000, Layer1 Grad Norm: 21.6311, Layer2 Grad Norm: 37.2884
Epoch 47/50, Loss: 250.9893, LR: 0.100000, Layer1 Grad Norm: 21.4473, Layer2 Grad Norm: 36.9365
Epoch 48/50, Loss: 235.6573, LR: 0.100000, Layer1 Grad Norm: 21.2200, Layer2 Grad Norm: 36.5086
Epoch 49/50, Loss: 220.6563, LR: 0.100000, Layer1 Grad Norm: 20.9488, Layer2 Grad Norm: 36.0045
Epoch 50/50, Loss: 206.0228, LR: 0.100000, Layer1 Grad Norm: 20.6338, Layer2 Grad Norm: 35.4242
Step 50: Effective LR: 0.011817
Step 50: Effective LR: 0.058373
Step 50: Effective LR: 0.005882
Step 50: Effective LR: 0.002374
Target: tensor([10., 28., 40.])
Predictions: tensor([ 9.2604, 15.6241, 18.4510])How did chosing LeakyReLU instead of ReLU help with the issue of dead parameters?
The LeakyReLU activation function allows a small, non-zero gradient when the input is negative, which helps to prevent the “dying ReLU” problem where neurons can become inactive and stop learning. In contrast, the ReLU activation function outputs zero for any negative input, which can lead to dead neurons if the weights are updated in such a way that they always produce negative inputs. By using LeakyReLU, we ensure that even when the input is negative, there is still a small gradient that allows the parameters to continue updating and learning, thus preventing them from becoming dead.
Comments