Show Code
# import packages
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn# import packages
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nnWe will work with the following dataset: X = [[1, 2, 3], [7, 5, 3], [9, 6, 4]] Y = [10, 28, 40]
Build a pytorch model to find the values fo weights and bias satisfying the following equation: \[y = w1*x1 + w2*x2 + w3*x3 + b\]
# define the dataset
X = np.array([[1, 2, 3], [7, 5, 3], [9, 6, 4]], dtype=float)
Y = np.array([10, 28, 40], dtype=float)Tensors are the core data structure in PyTorch..
So the first step is to convert our data into tensors. We can do this using the torch.tensor() function.
X = torch.tensor(X, dtype=torch.float32)
Y = torch.tensor(Y, dtype=torch.float32).reshape(-1, 1)# define the model
model = nn.Linear(in_features=3, out_features=1)# define the loss function
loss_fn = nn.MSELoss()After we created and defined the loss function, we need to define the optimizer. The optimizer is responsible for updating the weights and bias of the model during training. We can use the torch.optim module to define our optimizer. In this example, we will use the Stochastic Gradient Descent (SGD) optimizer.
torch.optim.SGD: means we are using the Stochastic Gradient Descent optimizer. model.parameters(): this gives the optimizer access to all learnable weights in your model. lr=0.01: this sets the learning rate.
optimizer.step(): performs this —> new_weight = old_weight - lr * gradient
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)def train(model, X, Y, loss_fn, optimizer, epochs=20):
losses = []
# reset the model parameters before training
model.apply(lambda m: m.reset_parameters() if hasattr(m, 'reset_parameters') else None)
for epoch in range(epochs):
# forward pass
predictions = model(X)
# calculate the loss
loss = loss_fn(predictions, Y)
# zero the gradients
optimizer.zero_grad()
# backward pass
loss.backward()
# INVESTIGATION: Access gradients here
# model[0] is the first Linear layer, model[2] is the second Linear layer
layer1_grad_norm = model[0].weight.grad.norm().item()
layer2_grad_norm = model[2].weight.grad.norm().item()
print(f"Epoch {epoch+1}/{epochs}, Loss: {loss.item():.4f}, Layer1 Grad Norm: {layer1_grad_norm:.4f}, Layer2 Grad Norm: {layer2_grad_norm:.4f}")
# update the weights
optimizer.step()
losses.append(loss.item())
print(f"Target: {Y.flatten()}\nPredictions: {predictions.detach().flatten()}")
return losses# verify the shapes of the input and output are matching
print(model(X).shape, Y.shape)torch.Size([3, 1]) torch.Size([3, 1])losses = train(model, X, Y, loss_fn, optimizer, epochs=20)Epoch 1/20, Loss: 818.9951
Epoch 2/20, Loss: 590.9524
Epoch 3/20, Loss: 426.6581
Epoch 4/20, Loss: 308.2915
Epoch 5/20, Loss: 223.0135
Epoch 6/20, Loss: 161.5744
Epoch 7/20, Loss: 117.3101
Epoch 8/20, Loss: 85.4194
Epoch 9/20, Loss: 62.4433
Epoch 10/20, Loss: 45.8897
Epoch 11/20, Loss: 33.9633
Epoch 12/20, Loss: 25.3705
Epoch 13/20, Loss: 19.1794
Epoch 14/20, Loss: 14.7187
Epoch 15/20, Loss: 11.5046
Epoch 16/20, Loss: 9.1887
Epoch 17/20, Loss: 7.5198
Epoch 18/20, Loss: 6.3171
Epoch 19/20, Loss: 5.4503
Epoch 20/20, Loss: 4.8254
Target: tensor([10., 28., 40.])
Predictions: tensor([10.0808, 28.9985, 36.3295])# plot the loss curve
plt.plot(losses)
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("Loss Curve")
plt.show()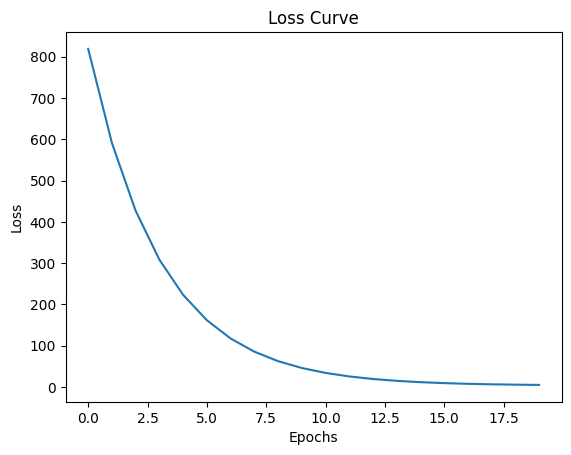
We did not use any hidden layers in our model, the results are acceptable but not great. We can improve the results by adding hidden layers to our model.
the classe nn.Sequential is a container that allows us to stack layers together. We will define the first layer with 3 input features and 5 output features, and the second layer with 5 input features and 1 output feature.
nn.ReLU(): is passing the output of the first layer through a non-linear activation function called ReLU (Rectified Linear Unit).
torch.manual_seed(42)
model_11 = nn.Sequential(
nn.Linear(in_features=3, out_features=5),
nn.ReLU(),
nn.Linear(in_features=5, out_features=1)
)
optimizer_11 = torch.optim.SGD(model_11.parameters(), lr=0.001)
losses_11 = train(model_11, X, Y, loss_fn, optimizer_11, epochs=20)
# plot the loss curve
plt.plot(losses_11)
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("Loss Curve")
plt.show()Epoch 1/20, Loss: 866.3484, Layer1 Grad Norm: 180.3140, Layer2 Grad Norm: 328.2925
Epoch 2/20, Loss: 735.9243, Layer1 Grad Norm: 195.5679, Layer2 Grad Norm: 292.6555
Epoch 3/20, Loss: 595.5496, Layer1 Grad Norm: 282.5869, Layer2 Grad Norm: 332.0929
Epoch 4/20, Loss: 386.4724, Layer1 Grad Norm: 337.5971, Layer2 Grad Norm: 361.7924
Epoch 5/20, Loss: 151.9379, Layer1 Grad Norm: 286.4894, Layer2 Grad Norm: 297.1678
Epoch 6/20, Loss: 22.5939, Layer1 Grad Norm: 126.5312, Layer2 Grad Norm: 129.6781
Epoch 7/20, Loss: 3.3519, Layer1 Grad Norm: 16.6935, Layer2 Grad Norm: 16.8021
Epoch 8/20, Loss: 3.0633, Layer1 Grad Norm: 1.5794, Layer2 Grad Norm: 0.3773
Epoch 9/20, Loss: 3.0607, Layer1 Grad Norm: 1.5308, Layer2 Grad Norm: 0.3532
Epoch 10/20, Loss: 3.0581, Layer1 Grad Norm: 1.5190, Layer2 Grad Norm: 0.3501
Epoch 11/20, Loss: 3.0556, Layer1 Grad Norm: 1.5074, Layer2 Grad Norm: 0.3470
Epoch 12/20, Loss: 3.0531, Layer1 Grad Norm: 1.4960, Layer2 Grad Norm: 0.3439
Epoch 13/20, Loss: 3.0507, Layer1 Grad Norm: 1.4849, Layer2 Grad Norm: 0.3408
Epoch 14/20, Loss: 3.0483, Layer1 Grad Norm: 1.4739, Layer2 Grad Norm: 0.3379
Epoch 15/20, Loss: 3.0460, Layer1 Grad Norm: 1.4632, Layer2 Grad Norm: 0.3349
Epoch 16/20, Loss: 3.0436, Layer1 Grad Norm: 1.4526, Layer2 Grad Norm: 0.3321
Epoch 17/20, Loss: 3.0413, Layer1 Grad Norm: 1.4422, Layer2 Grad Norm: 0.3291
Epoch 18/20, Loss: 3.0390, Layer1 Grad Norm: 1.4320, Layer2 Grad Norm: 0.3264
Epoch 19/20, Loss: 3.0368, Layer1 Grad Norm: 1.4221, Layer2 Grad Norm: 0.3236
Epoch 20/20, Loss: 3.0346, Layer1 Grad Norm: 1.4123, Layer2 Grad Norm: 0.3209
Target: tensor([10., 28., 40.])
Predictions: tensor([ 9.6553, 30.3903, 38.1913])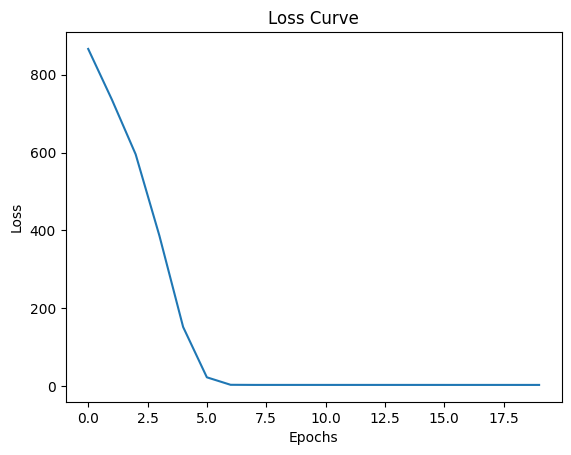
In the abve example, we used ReLU as the activation function. Let’s see what happens if we use softmax instead of ReLU.
model_sof = nn.Sequential(
nn.Linear(in_features=3, out_features=5),
nn.Softmax(dim=1),
nn.Linear(in_features=5, out_features=1)
)
optimizer_sof = torch.optim.SGD(model_sof.parameters(), lr=0.001)
losses_sof = train(model_sof, X, Y, loss_fn, optimizer_sof, epochs=200)
# plot the loss curve
plt.plot(losses_sof)
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("Loss Curve")
plt.show()Epoch 1/200, Loss: 844.4050, Layer1 Grad Norm: 41.4294, Layer2 Grad Norm: 38.2125
Epoch 2/200, Loss: 838.6600, Layer1 Grad Norm: 29.0350, Layer2 Grad Norm: 40.6277
Epoch 3/200, Loss: 833.4712, Layer1 Grad Norm: 22.8838, Layer2 Grad Norm: 41.9305
Epoch 4/200, Loss: 828.4759, Layer1 Grad Norm: 19.3376, Layer2 Grad Norm: 42.7344
Epoch 5/200, Loss: 823.5685, Layer1 Grad Norm: 17.0787, Layer2 Grad Norm: 43.2856
Epoch 6/200, Loss: 818.7094, Layer1 Grad Norm: 15.5513, Layer2 Grad Norm: 43.6921
Epoch 7/200, Loss: 813.8809, Layer1 Grad Norm: 14.4784, Layer2 Grad Norm: 44.0070
Epoch 8/200, Loss: 809.0740, Layer1 Grad Norm: 13.7021, Layer2 Grad Norm: 44.2586
Epoch 9/200, Loss: 804.2849, Layer1 Grad Norm: 13.1239, Layer2 Grad Norm: 44.4628
Epoch 10/200, Loss: 799.5108, Layer1 Grad Norm: 12.6794, Layer2 Grad Norm: 44.6294
Epoch 11/200, Loss: 794.7518, Layer1 Grad Norm: 12.3261, Layer2 Grad Norm: 44.7647
Epoch 12/200, Loss: 790.0076, Layer1 Grad Norm: 12.0360, Layer2 Grad Norm: 44.8732
Epoch 13/200, Loss: 785.2790, Layer1 Grad Norm: 11.7916, Layer2 Grad Norm: 44.9583
Epoch 14/200, Loss: 780.5667, Layer1 Grad Norm: 11.5817, Layer2 Grad Norm: 45.0230
Epoch 15/200, Loss: 775.8716, Layer1 Grad Norm: 11.3995, Layer2 Grad Norm: 45.0697
Epoch 16/200, Loss: 771.1945, Layer1 Grad Norm: 11.2409, Layer2 Grad Norm: 45.1005
Epoch 17/200, Loss: 766.5363, Layer1 Grad Norm: 11.1031, Layer2 Grad Norm: 45.1175
Epoch 18/200, Loss: 761.8975, Layer1 Grad Norm: 10.9843, Layer2 Grad Norm: 45.1223
Epoch 19/200, Loss: 757.2786, Layer1 Grad Norm: 10.8826, Layer2 Grad Norm: 45.1163
Epoch 20/200, Loss: 752.6804, Layer1 Grad Norm: 10.7966, Layer2 Grad Norm: 45.1010
Epoch 21/200, Loss: 748.1030, Layer1 Grad Norm: 10.7249, Layer2 Grad Norm: 45.0773
Epoch 22/200, Loss: 743.5469, Layer1 Grad Norm: 10.6658, Layer2 Grad Norm: 45.0462
Epoch 23/200, Loss: 739.0126, Layer1 Grad Norm: 10.6176, Layer2 Grad Norm: 45.0086
Epoch 24/200, Loss: 734.5002, Layer1 Grad Norm: 10.5787, Layer2 Grad Norm: 44.9651
Epoch 25/200, Loss: 730.0099, Layer1 Grad Norm: 10.5474, Layer2 Grad Norm: 44.9163
Epoch 26/200, Loss: 725.5422, Layer1 Grad Norm: 10.5217, Layer2 Grad Norm: 44.8627
Epoch 27/200, Loss: 721.0974, Layer1 Grad Norm: 10.5000, Layer2 Grad Norm: 44.8048
Epoch 28/200, Loss: 716.6753, Layer1 Grad Norm: 10.4808, Layer2 Grad Norm: 44.7428
Epoch 29/200, Loss: 712.2766, Layer1 Grad Norm: 10.4622, Layer2 Grad Norm: 44.6770
Epoch 30/200, Loss: 707.9014, Layer1 Grad Norm: 10.4428, Layer2 Grad Norm: 44.6076
Epoch 31/200, Loss: 703.5500, Layer1 Grad Norm: 10.4212, Layer2 Grad Norm: 44.5348
Epoch 32/200, Loss: 699.2228, Layer1 Grad Norm: 10.3962, Layer2 Grad Norm: 44.4588
Epoch 33/200, Loss: 694.9201, Layer1 Grad Norm: 10.3665, Layer2 Grad Norm: 44.3796
Epoch 34/200, Loss: 690.6421, Layer1 Grad Norm: 10.3312, Layer2 Grad Norm: 44.2975
Epoch 35/200, Loss: 686.3892, Layer1 Grad Norm: 10.2896, Layer2 Grad Norm: 44.2123
Epoch 36/200, Loss: 682.1618, Layer1 Grad Norm: 10.2406, Layer2 Grad Norm: 44.1242
Epoch 37/200, Loss: 677.9601, Layer1 Grad Norm: 10.1843, Layer2 Grad Norm: 44.0333
Epoch 38/200, Loss: 673.7844, Layer1 Grad Norm: 10.1198, Layer2 Grad Norm: 43.9396
Epoch 39/200, Loss: 669.6353, Layer1 Grad Norm: 10.0473, Layer2 Grad Norm: 43.8431
Epoch 40/200, Loss: 665.5128, Layer1 Grad Norm: 9.9665, Layer2 Grad Norm: 43.7439
Epoch 41/200, Loss: 661.4174, Layer1 Grad Norm: 9.8777, Layer2 Grad Norm: 43.6421
Epoch 42/200, Loss: 657.3492, Layer1 Grad Norm: 9.7809, Layer2 Grad Norm: 43.5377
Epoch 43/200, Loss: 653.3087, Layer1 Grad Norm: 9.6765, Layer2 Grad Norm: 43.4307
Epoch 44/200, Loss: 649.2961, Layer1 Grad Norm: 9.5648, Layer2 Grad Norm: 43.3213
Epoch 45/200, Loss: 645.3115, Layer1 Grad Norm: 9.4464, Layer2 Grad Norm: 43.2095
Epoch 46/200, Loss: 641.3550, Layer1 Grad Norm: 9.3216, Layer2 Grad Norm: 43.0954
Epoch 47/200, Loss: 637.4271, Layer1 Grad Norm: 9.1911, Layer2 Grad Norm: 42.9790
Epoch 48/200, Loss: 633.5276, Layer1 Grad Norm: 9.0554, Layer2 Grad Norm: 42.8605
Epoch 49/200, Loss: 629.6568, Layer1 Grad Norm: 8.9151, Layer2 Grad Norm: 42.7399
Epoch 50/200, Loss: 625.8148, Layer1 Grad Norm: 8.7710, Layer2 Grad Norm: 42.6174
Epoch 51/200, Loss: 622.0015, Layer1 Grad Norm: 8.6234, Layer2 Grad Norm: 42.4929
Epoch 52/200, Loss: 618.2172, Layer1 Grad Norm: 8.4730, Layer2 Grad Norm: 42.3668
Epoch 53/200, Loss: 614.4617, Layer1 Grad Norm: 8.3204, Layer2 Grad Norm: 42.2389
Epoch 54/200, Loss: 610.7349, Layer1 Grad Norm: 8.1659, Layer2 Grad Norm: 42.1095
Epoch 55/200, Loss: 607.0370, Layer1 Grad Norm: 8.0103, Layer2 Grad Norm: 41.9786
Epoch 56/200, Loss: 603.3677, Layer1 Grad Norm: 7.8539, Layer2 Grad Norm: 41.8463
Epoch 57/200, Loss: 599.7272, Layer1 Grad Norm: 7.6971, Layer2 Grad Norm: 41.7128
Epoch 58/200, Loss: 596.1152, Layer1 Grad Norm: 7.5402, Layer2 Grad Norm: 41.5780
Epoch 59/200, Loss: 592.5317, Layer1 Grad Norm: 7.3838, Layer2 Grad Norm: 41.4422
Epoch 60/200, Loss: 588.9765, Layer1 Grad Norm: 7.2280, Layer2 Grad Norm: 41.3053
Epoch 61/200, Loss: 585.4495, Layer1 Grad Norm: 7.0731, Layer2 Grad Norm: 41.1676
Epoch 62/200, Loss: 581.9506, Layer1 Grad Norm: 6.9196, Layer2 Grad Norm: 41.0290
Epoch 63/200, Loss: 578.4795, Layer1 Grad Norm: 6.7673, Layer2 Grad Norm: 40.8896
Epoch 64/200, Loss: 575.0361, Layer1 Grad Norm: 6.6165, Layer2 Grad Norm: 40.7496
Epoch 65/200, Loss: 571.6203, Layer1 Grad Norm: 6.4678, Layer2 Grad Norm: 40.6090
Epoch 66/200, Loss: 568.2319, Layer1 Grad Norm: 6.3207, Layer2 Grad Norm: 40.4678
Epoch 67/200, Loss: 564.8706, Layer1 Grad Norm: 6.1756, Layer2 Grad Norm: 40.3261
Epoch 68/200, Loss: 561.5363, Layer1 Grad Norm: 6.0326, Layer2 Grad Norm: 40.1840
Epoch 69/200, Loss: 558.2288, Layer1 Grad Norm: 5.8919, Layer2 Grad Norm: 40.0416
Epoch 70/200, Loss: 554.9480, Layer1 Grad Norm: 5.7532, Layer2 Grad Norm: 39.8989
Epoch 71/200, Loss: 551.6935, Layer1 Grad Norm: 5.6167, Layer2 Grad Norm: 39.7559
Epoch 72/200, Loss: 548.4653, Layer1 Grad Norm: 5.4827, Layer2 Grad Norm: 39.6127
Epoch 73/200, Loss: 545.2631, Layer1 Grad Norm: 5.3508, Layer2 Grad Norm: 39.4694
Epoch 74/200, Loss: 542.0866, Layer1 Grad Norm: 5.2211, Layer2 Grad Norm: 39.3260
Epoch 75/200, Loss: 538.9357, Layer1 Grad Norm: 5.0937, Layer2 Grad Norm: 39.1825
Epoch 76/200, Loss: 535.8102, Layer1 Grad Norm: 4.9686, Layer2 Grad Norm: 39.0389
Epoch 77/200, Loss: 532.7100, Layer1 Grad Norm: 4.8457, Layer2 Grad Norm: 38.8954
Epoch 78/200, Loss: 529.6347, Layer1 Grad Norm: 4.7250, Layer2 Grad Norm: 38.7519
Epoch 79/200, Loss: 526.5842, Layer1 Grad Norm: 4.6064, Layer2 Grad Norm: 38.6085
Epoch 80/200, Loss: 523.5582, Layer1 Grad Norm: 4.4901, Layer2 Grad Norm: 38.4651
Epoch 81/200, Loss: 520.5566, Layer1 Grad Norm: 4.3757, Layer2 Grad Norm: 38.3219
Epoch 82/200, Loss: 517.5792, Layer1 Grad Norm: 4.2634, Layer2 Grad Norm: 38.1789
Epoch 83/200, Loss: 514.6258, Layer1 Grad Norm: 4.1531, Layer2 Grad Norm: 38.0360
Epoch 84/200, Loss: 511.6961, Layer1 Grad Norm: 4.0448, Layer2 Grad Norm: 37.8934
Epoch 85/200, Loss: 508.7899, Layer1 Grad Norm: 3.9381, Layer2 Grad Norm: 37.7509
Epoch 86/200, Loss: 505.9072, Layer1 Grad Norm: 3.8334, Layer2 Grad Norm: 37.6088
Epoch 87/200, Loss: 503.0476, Layer1 Grad Norm: 3.7304, Layer2 Grad Norm: 37.4668
Epoch 88/200, Loss: 500.2110, Layer1 Grad Norm: 3.6294, Layer2 Grad Norm: 37.3252
Epoch 89/200, Loss: 497.3972, Layer1 Grad Norm: 3.5299, Layer2 Grad Norm: 37.1838
Epoch 90/200, Loss: 494.6060, Layer1 Grad Norm: 3.4320, Layer2 Grad Norm: 37.0428
Epoch 91/200, Loss: 491.8372, Layer1 Grad Norm: 3.3357, Layer2 Grad Norm: 36.9021
Epoch 92/200, Loss: 489.0905, Layer1 Grad Norm: 3.2408, Layer2 Grad Norm: 36.7617
Epoch 93/200, Loss: 486.3659, Layer1 Grad Norm: 3.1477, Layer2 Grad Norm: 36.6217
Epoch 94/200, Loss: 483.6631, Layer1 Grad Norm: 3.0556, Layer2 Grad Norm: 36.4820
Epoch 95/200, Loss: 480.9820, Layer1 Grad Norm: 2.9651, Layer2 Grad Norm: 36.3427
Epoch 96/200, Loss: 478.3224, Layer1 Grad Norm: 2.8759, Layer2 Grad Norm: 36.2038
Epoch 97/200, Loss: 475.6841, Layer1 Grad Norm: 2.7880, Layer2 Grad Norm: 36.0653
Epoch 98/200, Loss: 473.0667, Layer1 Grad Norm: 2.7012, Layer2 Grad Norm: 35.9272
Epoch 99/200, Loss: 470.4703, Layer1 Grad Norm: 2.6154, Layer2 Grad Norm: 35.7895
Epoch 100/200, Loss: 467.8948, Layer1 Grad Norm: 2.5310, Layer2 Grad Norm: 35.6522
Epoch 101/200, Loss: 465.3398, Layer1 Grad Norm: 2.4475, Layer2 Grad Norm: 35.5154
Epoch 102/200, Loss: 462.8051, Layer1 Grad Norm: 2.3649, Layer2 Grad Norm: 35.3790
Epoch 103/200, Loss: 460.2907, Layer1 Grad Norm: 2.2834, Layer2 Grad Norm: 35.2430
Epoch 104/200, Loss: 457.7963, Layer1 Grad Norm: 2.2028, Layer2 Grad Norm: 35.1075
Epoch 105/200, Loss: 455.3218, Layer1 Grad Norm: 2.1232, Layer2 Grad Norm: 34.9724
Epoch 106/200, Loss: 452.8671, Layer1 Grad Norm: 2.0441, Layer2 Grad Norm: 34.8378
Epoch 107/200, Loss: 450.4318, Layer1 Grad Norm: 1.9660, Layer2 Grad Norm: 34.7036
Epoch 108/200, Loss: 448.0160, Layer1 Grad Norm: 1.8887, Layer2 Grad Norm: 34.5700
Epoch 109/200, Loss: 445.6192, Layer1 Grad Norm: 1.8120, Layer2 Grad Norm: 34.4368
Epoch 110/200, Loss: 443.2417, Layer1 Grad Norm: 1.7360, Layer2 Grad Norm: 34.3040
Epoch 111/200, Loss: 440.8829, Layer1 Grad Norm: 1.6605, Layer2 Grad Norm: 34.1718
Epoch 112/200, Loss: 438.5429, Layer1 Grad Norm: 1.5857, Layer2 Grad Norm: 34.0401
Epoch 113/200, Loss: 436.2214, Layer1 Grad Norm: 1.5113, Layer2 Grad Norm: 33.9088
Epoch 114/200, Loss: 433.9183, Layer1 Grad Norm: 1.4374, Layer2 Grad Norm: 33.7780
Epoch 115/200, Loss: 431.6335, Layer1 Grad Norm: 1.3640, Layer2 Grad Norm: 33.6477
Epoch 116/200, Loss: 429.3668, Layer1 Grad Norm: 1.2911, Layer2 Grad Norm: 33.5180
Epoch 117/200, Loss: 427.1179, Layer1 Grad Norm: 1.2185, Layer2 Grad Norm: 33.3887
Epoch 118/200, Loss: 424.8868, Layer1 Grad Norm: 1.1462, Layer2 Grad Norm: 33.2599
Epoch 119/200, Loss: 422.6734, Layer1 Grad Norm: 1.0743, Layer2 Grad Norm: 33.1317
Epoch 120/200, Loss: 420.4774, Layer1 Grad Norm: 1.0025, Layer2 Grad Norm: 33.0040
Epoch 121/200, Loss: 418.2987, Layer1 Grad Norm: 0.9311, Layer2 Grad Norm: 32.8767
Epoch 122/200, Loss: 416.1372, Layer1 Grad Norm: 0.8598, Layer2 Grad Norm: 32.7500
Epoch 123/200, Loss: 413.9927, Layer1 Grad Norm: 0.7886, Layer2 Grad Norm: 32.6238
Epoch 124/200, Loss: 411.8651, Layer1 Grad Norm: 0.7176, Layer2 Grad Norm: 32.4982
Epoch 125/200, Loss: 409.7541, Layer1 Grad Norm: 0.6467, Layer2 Grad Norm: 32.3730
Epoch 126/200, Loss: 407.6597, Layer1 Grad Norm: 0.5756, Layer2 Grad Norm: 32.2484
Epoch 127/200, Loss: 405.5818, Layer1 Grad Norm: 0.5050, Layer2 Grad Norm: 32.1243
Epoch 128/200, Loss: 403.5201, Layer1 Grad Norm: 0.4341, Layer2 Grad Norm: 32.0008
Epoch 129/200, Loss: 401.4745, Layer1 Grad Norm: 0.3634, Layer2 Grad Norm: 31.8778
Epoch 130/200, Loss: 399.4449, Layer1 Grad Norm: 0.2931, Layer2 Grad Norm: 31.7553
Epoch 131/200, Loss: 397.4312, Layer1 Grad Norm: 0.2232, Layer2 Grad Norm: 31.6334
Epoch 132/200, Loss: 395.4331, Layer1 Grad Norm: 0.1548, Layer2 Grad Norm: 31.5120
Epoch 133/200, Loss: 393.4506, Layer1 Grad Norm: 0.0914, Layer2 Grad Norm: 31.3912
Epoch 134/200, Loss: 391.4834, Layer1 Grad Norm: 0.0571, Layer2 Grad Norm: 31.2709
Epoch 135/200, Loss: 389.5316, Layer1 Grad Norm: 0.0934, Layer2 Grad Norm: 31.1511
Epoch 136/200, Loss: 387.5949, Layer1 Grad Norm: 0.1580, Layer2 Grad Norm: 31.0319
Epoch 137/200, Loss: 385.6731, Layer1 Grad Norm: 0.2284, Layer2 Grad Norm: 30.9133
Epoch 138/200, Loss: 383.7663, Layer1 Grad Norm: 0.3008, Layer2 Grad Norm: 30.7953
Epoch 139/200, Loss: 381.8741, Layer1 Grad Norm: 0.3744, Layer2 Grad Norm: 30.6778
Epoch 140/200, Loss: 379.9965, Layer1 Grad Norm: 0.4492, Layer2 Grad Norm: 30.5608
Epoch 141/200, Loss: 378.1333, Layer1 Grad Norm: 0.5246, Layer2 Grad Norm: 30.4445
Epoch 142/200, Loss: 376.2844, Layer1 Grad Norm: 0.6011, Layer2 Grad Norm: 30.3287
Epoch 143/200, Loss: 374.4496, Layer1 Grad Norm: 0.6782, Layer2 Grad Norm: 30.2135
Epoch 144/200, Loss: 372.6289, Layer1 Grad Norm: 0.7563, Layer2 Grad Norm: 30.0989
Epoch 145/200, Loss: 370.8220, Layer1 Grad Norm: 0.8352, Layer2 Grad Norm: 29.9848
Epoch 146/200, Loss: 369.0288, Layer1 Grad Norm: 0.9150, Layer2 Grad Norm: 29.8714
Epoch 147/200, Loss: 367.2493, Layer1 Grad Norm: 0.9959, Layer2 Grad Norm: 29.7585
Epoch 148/200, Loss: 365.4832, Layer1 Grad Norm: 1.0778, Layer2 Grad Norm: 29.6463
Epoch 149/200, Loss: 363.7304, Layer1 Grad Norm: 1.1606, Layer2 Grad Norm: 29.5347
Epoch 150/200, Loss: 361.9908, Layer1 Grad Norm: 1.2448, Layer2 Grad Norm: 29.4237
Epoch 151/200, Loss: 360.2642, Layer1 Grad Norm: 1.3302, Layer2 Grad Norm: 29.3133
Epoch 152/200, Loss: 358.5505, Layer1 Grad Norm: 1.4168, Layer2 Grad Norm: 29.2035
Epoch 153/200, Loss: 356.8496, Layer1 Grad Norm: 1.5047, Layer2 Grad Norm: 29.0944
Epoch 154/200, Loss: 355.1613, Layer1 Grad Norm: 1.5942, Layer2 Grad Norm: 28.9859
Epoch 155/200, Loss: 353.4854, Layer1 Grad Norm: 1.6852, Layer2 Grad Norm: 28.8780
Epoch 156/200, Loss: 351.8219, Layer1 Grad Norm: 1.7776, Layer2 Grad Norm: 28.7708
Epoch 157/200, Loss: 350.1706, Layer1 Grad Norm: 1.8714, Layer2 Grad Norm: 28.6643
Epoch 158/200, Loss: 348.5312, Layer1 Grad Norm: 1.9675, Layer2 Grad Norm: 28.5584
Epoch 159/200, Loss: 346.9038, Layer1 Grad Norm: 2.0651, Layer2 Grad Norm: 28.4533
Epoch 160/200, Loss: 345.2881, Layer1 Grad Norm: 2.1644, Layer2 Grad Norm: 28.3488
Epoch 161/200, Loss: 343.6839, Layer1 Grad Norm: 2.2662, Layer2 Grad Norm: 28.2450
Epoch 162/200, Loss: 342.0913, Layer1 Grad Norm: 2.3698, Layer2 Grad Norm: 28.1420
Epoch 163/200, Loss: 340.5098, Layer1 Grad Norm: 2.4755, Layer2 Grad Norm: 28.0397
Epoch 164/200, Loss: 338.9395, Layer1 Grad Norm: 2.5835, Layer2 Grad Norm: 27.9381
Epoch 165/200, Loss: 337.3802, Layer1 Grad Norm: 2.6939, Layer2 Grad Norm: 27.8372
Epoch 166/200, Loss: 335.8316, Layer1 Grad Norm: 2.8068, Layer2 Grad Norm: 27.7372
Epoch 167/200, Loss: 334.2938, Layer1 Grad Norm: 2.9221, Layer2 Grad Norm: 27.6379
Epoch 168/200, Loss: 332.7663, Layer1 Grad Norm: 3.0403, Layer2 Grad Norm: 27.5395
Epoch 169/200, Loss: 331.2491, Layer1 Grad Norm: 3.1612, Layer2 Grad Norm: 27.4418
Epoch 170/200, Loss: 329.7421, Layer1 Grad Norm: 3.2847, Layer2 Grad Norm: 27.3451
Epoch 171/200, Loss: 328.2450, Layer1 Grad Norm: 3.4116, Layer2 Grad Norm: 27.2491
Epoch 172/200, Loss: 326.7577, Layer1 Grad Norm: 3.5416, Layer2 Grad Norm: 27.1541
Epoch 173/200, Loss: 325.2799, Layer1 Grad Norm: 3.6747, Layer2 Grad Norm: 27.0599
Epoch 174/200, Loss: 323.8115, Layer1 Grad Norm: 3.8112, Layer2 Grad Norm: 26.9667
Epoch 175/200, Loss: 322.3523, Layer1 Grad Norm: 3.9513, Layer2 Grad Norm: 26.8745
Epoch 176/200, Loss: 320.9021, Layer1 Grad Norm: 4.0947, Layer2 Grad Norm: 26.7832
Epoch 177/200, Loss: 319.4607, Layer1 Grad Norm: 4.2419, Layer2 Grad Norm: 26.6930
Epoch 178/200, Loss: 318.0277, Layer1 Grad Norm: 4.3930, Layer2 Grad Norm: 26.6038
Epoch 179/200, Loss: 316.6032, Layer1 Grad Norm: 4.5478, Layer2 Grad Norm: 26.5156
Epoch 180/200, Loss: 315.1867, Layer1 Grad Norm: 4.7067, Layer2 Grad Norm: 26.4286
Epoch 181/200, Loss: 313.7782, Layer1 Grad Norm: 4.8695, Layer2 Grad Norm: 26.3428
Epoch 182/200, Loss: 312.3772, Layer1 Grad Norm: 5.0366, Layer2 Grad Norm: 26.2581
Epoch 183/200, Loss: 310.9837, Layer1 Grad Norm: 5.2076, Layer2 Grad Norm: 26.1746
Epoch 184/200, Loss: 309.5972, Layer1 Grad Norm: 5.3834, Layer2 Grad Norm: 26.0925
Epoch 185/200, Loss: 308.2176, Layer1 Grad Norm: 5.5628, Layer2 Grad Norm: 26.0116
Epoch 186/200, Loss: 306.8446, Layer1 Grad Norm: 5.7464, Layer2 Grad Norm: 25.9321
Epoch 187/200, Loss: 305.4780, Layer1 Grad Norm: 5.9343, Layer2 Grad Norm: 25.8540
Epoch 188/200, Loss: 304.1173, Layer1 Grad Norm: 6.1263, Layer2 Grad Norm: 25.7774
Epoch 189/200, Loss: 302.7624, Layer1 Grad Norm: 6.3220, Layer2 Grad Norm: 25.7022
Epoch 190/200, Loss: 301.4129, Layer1 Grad Norm: 6.5213, Layer2 Grad Norm: 25.6286
Epoch 191/200, Loss: 300.0685, Layer1 Grad Norm: 6.7240, Layer2 Grad Norm: 25.5567
Epoch 192/200, Loss: 298.7289, Layer1 Grad Norm: 6.9299, Layer2 Grad Norm: 25.4864
Epoch 193/200, Loss: 297.3938, Layer1 Grad Norm: 7.1383, Layer2 Grad Norm: 25.4178
Epoch 194/200, Loss: 296.0629, Layer1 Grad Norm: 7.3486, Layer2 Grad Norm: 25.3510
Epoch 195/200, Loss: 294.7358, Layer1 Grad Norm: 7.5606, Layer2 Grad Norm: 25.2861
Epoch 196/200, Loss: 293.4123, Layer1 Grad Norm: 7.7731, Layer2 Grad Norm: 25.2230
Epoch 197/200, Loss: 292.0921, Layer1 Grad Norm: 7.9856, Layer2 Grad Norm: 25.1618
Epoch 198/200, Loss: 290.7748, Layer1 Grad Norm: 8.1968, Layer2 Grad Norm: 25.1026
Epoch 199/200, Loss: 289.4602, Layer1 Grad Norm: 8.4056, Layer2 Grad Norm: 25.0454
Epoch 200/200, Loss: 288.1480, Layer1 Grad Norm: 8.6110, Layer2 Grad Norm: 24.9902
Target: tensor([10., 28., 40.])
Predictions: tensor([12.6942, 14.1835, 14.1874])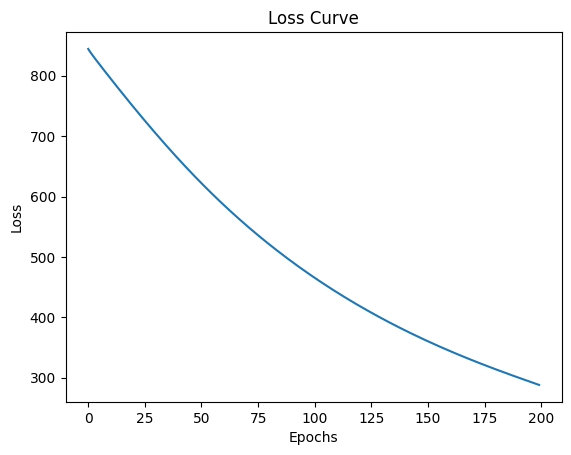
It did not train, because softmax is not a good choice for activation function in this case. Softmax turns the output of the first layer into a probability distribution, equation: \[softmax(x_i) = \frac{e^{x_i}}{\sum_{j} e^{x_j}}\]
Consequences: - Outputs are between 0 and 1, and they sum up to 1. - The hidden layer only represents the relative importance of each feature, not the actual values. - Softmax constrained the hidden space - Reduced gradient flow
with torch.no_grad(): # disable gradient calculation
x_tensor = X.clone().detach().type(torch.float32)
hidden_relu = model_11[0:2](x_tensor) # [0:2] slices the model to include only the first two layers
hidden_softmax = model_sof[0:2](x_tensor)
print("ReLU activations:\n", hidden_relu)
print("ReLU activations size:\n", hidden_relu.size())
print("Softmax activations:\n", hidden_softmax)ReLU activations:
tensor([[ 2.9187, 3.8785, 1.5274, 0.8169, 1.5696],
[10.9183, 12.1943, 0.0000, 0.0000, 4.3133],
[13.7070, 15.4393, 0.0000, 0.0000, 5.5125]])
ReLU activations size:
torch.Size([3, 5])
Softmax activations:
tensor([[8.2851e-01, 2.0480e-02, 9.0704e-02, 1.1774e-02, 4.8529e-02],
[9.8566e-01, 5.0014e-03, 1.0012e-03, 1.9745e-03, 6.3635e-03],
[9.9714e-01, 8.7960e-04, 1.0381e-04, 4.8818e-04, 1.3856e-03]])print("ReLU variance:", hidden_relu.var().item())
print("Softmax variance:", hidden_softmax.var().item())ReLU variance: 29.921340942382812
Softmax variance: 0.14739039540290833Now we will try with tanH activation function. The tanH function is defined as: \[tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}\] The tanH function outputs values between -1 and 1, which can help with training stability and convergence, but can it give better results than ReLU in this case? Let’s find out.
model_tanh = nn.Sequential(
nn.Linear(in_features=3, out_features=5),
nn.Tanh(),
nn.Linear(in_features=5, out_features=1)
)
optimizer_tanh = torch.optim.SGD(model_tanh.parameters(), lr=0.001)
losses_tanh = train(model_tanh, X, Y, loss_fn, optimizer_tanh, epochs=20)
# plot the loss curve
plt.plot(losses_tanh)
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("Loss Curve")
plt.show()Epoch 1/20, Loss: 851.4619, Layer1 Grad Norm: 14.4621, Layer2 Grad Norm: 106.6933
Epoch 2/20, Loss: 837.2038, Layer1 Grad Norm: 10.6261, Layer2 Grad Norm: 105.0900
Epoch 3/20, Loss: 823.3930, Layer1 Grad Norm: 10.4007, Layer2 Grad Norm: 103.9408
Epoch 4/20, Loss: 809.8214, Layer1 Grad Norm: 14.0775, Layer2 Grad Norm: 103.3453
Epoch 5/20, Loss: 796.3004, Layer1 Grad Norm: 17.2374, Layer2 Grad Norm: 103.1479
Epoch 6/20, Loss: 782.7731, Layer1 Grad Norm: 18.4882, Layer2 Grad Norm: 103.0584
Epoch 7/20, Loss: 769.2850, Layer1 Grad Norm: 18.4335, Layer2 Grad Norm: 102.8734
Epoch 8/20, Loss: 755.8992, Layer1 Grad Norm: 17.8916, Layer2 Grad Norm: 102.5371
Epoch 9/20, Loss: 742.6587, Layer1 Grad Norm: 17.3249, Layer2 Grad Norm: 102.0699
Epoch 10/20, Loss: 729.5860, Layer1 Grad Norm: 16.8996, Layer2 Grad Norm: 101.5073
Epoch 11/20, Loss: 716.6926, Layer1 Grad Norm: 16.6341, Layer2 Grad Norm: 100.8778
Epoch 12/20, Loss: 703.9844, Layer1 Grad Norm: 16.4910, Layer2 Grad Norm: 100.2004
Epoch 13/20, Loss: 691.4653, Layer1 Grad Norm: 16.4202, Layer2 Grad Norm: 99.4870
Epoch 14/20, Loss: 679.1390, Layer1 Grad Norm: 16.3760, Layer2 Grad Norm: 98.7449
Epoch 15/20, Loss: 667.0088, Layer1 Grad Norm: 16.3228, Layer2 Grad Norm: 97.9783
Epoch 16/20, Loss: 655.0784, Layer1 Grad Norm: 16.2355, Layer2 Grad Norm: 97.1902
Epoch 17/20, Loss: 643.3515, Layer1 Grad Norm: 16.0976, Layer2 Grad Norm: 96.3824
Epoch 18/20, Loss: 631.8320, Layer1 Grad Norm: 15.9004, Layer2 Grad Norm: 95.5565
Epoch 19/20, Loss: 620.5234, Layer1 Grad Norm: 15.6408, Layer2 Grad Norm: 94.7138
Epoch 20/20, Loss: 609.4288, Layer1 Grad Norm: 15.3201, Layer2 Grad Norm: 93.8559
Target: tensor([10., 28., 40.])
Predictions: tensor([3.6362, 4.7012, 4.7161])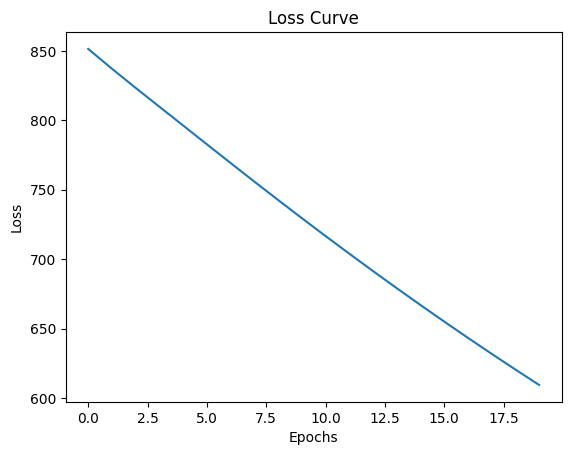
with torch.no_grad(): # disable gradient calculation
x_tensor = X.clone().detach().type(torch.float32)
hidden_relu = model_11[0:2](x_tensor) # [0:2] slices the model to include only the first two layers
hidden_tanh = model_tanh[0:2](x_tensor)
print("ReLU activations:\n", hidden_relu)
print("TanH activations:\n", hidden_tanh)ReLU activations:
tensor([[ 2.9187, 3.8785, 1.5274, 0.8169, 1.5696],
[10.9183, 12.1943, 0.0000, 0.0000, 4.3133],
[13.7070, 15.4393, 0.0000, 0.0000, 5.5125]])
TanH activations:
tensor([[ 0.7258, -0.8974, 0.7363, -0.3916, 0.8550],
[ 0.9990, -0.9982, 0.9932, -0.9997, 0.9887],
[ 0.9998, -0.9998, 0.9991, -1.0000, 0.9980]])print("ReLU variance:", hidden_relu.var().item())
print("TanH variance:", hidden_tanh.var().item())ReLU variance: 29.921340942382812
TanH variance: 0.8647297024726868Same with softmax, the tanH activations lower variance compared to ReLU, causing slower convergence and higher loss values, and leading to worse performance and slower training compared to ReLU.
Finally, we will try with sigmoid activation function. The sigmoid function is defined as: \[sigmoid(x) = \frac{1}{1 + e^{-x}}\] The sigmoid function outputs values between 0 and 1, which can help with training stability and convergence, but can it give better results than ReLU in this case? Let’s find out.
model_sigmoid = nn.Sequential(
nn.Linear(in_features=3, out_features=5),
nn.Sigmoid(),
nn.Linear(in_features=5, out_features=1)
)
optimizer_sigmoid = torch.optim.SGD(model_sigmoid.parameters(), lr=0.001)
losses_sigmoid = train(model_sigmoid, X, Y, loss_fn, optimizer_sigmoid, epochs=20)
# plot the loss curve
plt.plot(losses_sigmoid)
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("Loss Curve")
plt.show()Epoch 1/20, Loss: 829.7568, Layer1 Grad Norm: 55.1420, Layer2 Grad Norm: 67.8577
Epoch 2/20, Loss: 819.5628, Layer1 Grad Norm: 50.3613, Layer2 Grad Norm: 67.3689
Epoch 3/20, Loss: 809.8196, Layer1 Grad Norm: 50.2198, Layer2 Grad Norm: 67.8034
Epoch 4/20, Loss: 799.9503, Layer1 Grad Norm: 53.2566, Layer2 Grad Norm: 68.9174
Epoch 5/20, Loss: 789.6085, Layer1 Grad Norm: 55.9899, Layer2 Grad Norm: 70.6884
Epoch 6/20, Loss: 778.8330, Layer1 Grad Norm: 54.6840, Layer2 Grad Norm: 72.9436
Epoch 7/20, Loss: 768.0394, Layer1 Grad Norm: 49.2307, Layer2 Grad Norm: 75.1162
Epoch 8/20, Loss: 757.5726, Layer1 Grad Norm: 42.9666, Layer2 Grad Norm: 76.7264
Epoch 9/20, Loss: 747.4617, Layer1 Grad Norm: 38.0194, Layer2 Grad Norm: 77.7546
Epoch 10/20, Loss: 737.6082, Layer1 Grad Norm: 34.7047, Layer2 Grad Norm: 78.3786
Epoch 11/20, Loss: 727.9183, Layer1 Grad Norm: 32.8100, Layer2 Grad Norm: 78.7621
Epoch 12/20, Loss: 718.3184, Layer1 Grad Norm: 32.1071, Layer2 Grad Norm: 79.0237
Epoch 13/20, Loss: 708.7455, Layer1 Grad Norm: 32.3861, Layer2 Grad Norm: 79.2535
Epoch 14/20, Loss: 699.1418, Layer1 Grad Norm: 33.3579, Layer2 Grad Norm: 79.5247
Epoch 15/20, Loss: 689.4581, Layer1 Grad Norm: 34.5569, Layer2 Grad Norm: 79.8921
Epoch 16/20, Loss: 679.6707, Layer1 Grad Norm: 35.3545, Layer2 Grad Norm: 80.3731
Epoch 17/20, Loss: 669.7993, Layer1 Grad Norm: 35.1960, Layer2 Grad Norm: 80.9241
Epoch 18/20, Loss: 659.9080, Layer1 Grad Norm: 33.9354, Layer2 Grad Norm: 81.4476
Epoch 19/20, Loss: 650.0756, Layer1 Grad Norm: 31.8902, Layer2 Grad Norm: 81.8435
Epoch 20/20, Loss: 640.3629, Layer1 Grad Norm: 29.5379, Layer2 Grad Norm: 82.0591
Target: tensor([10., 28., 40.])
Predictions: tensor([3.2820, 3.9218, 3.9972])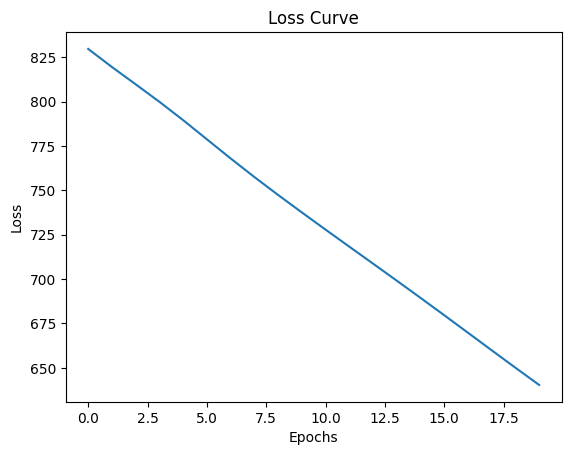
with torch.no_grad(): # disable gradient calculation
x_tensor = X.clone().detach().type(torch.float32)
hidden_relu = model_11[0:2](x_tensor) # [0:2] slices the model to include only the first two layers
hidden_sigmoid = model_sigmoid[0:2](x_tensor)
print("ReLU activations:\n", hidden_relu)
print("Sigmoid activations:\n", hidden_sigmoid)
print("ReLU variance:", hidden_relu.var().item())
print("Sigmoid variance:", hidden_sigmoid.var().item())ReLU activations:
tensor([[ 2.9187, 3.8785, 1.5274, 0.8169, 1.5696],
[10.9183, 12.1943, 0.0000, 0.0000, 4.3133],
[13.7070, 15.4393, 0.0000, 0.0000, 5.5125]])
Sigmoid activations:
tensor([[6.1468e-02, 7.7676e-02, 7.7624e-01, 1.2007e-01, 3.2386e-01],
[1.6804e-02, 2.6094e-03, 9.9437e-01, 1.6046e-03, 7.2175e-01],
[6.5273e-03, 5.6454e-04, 9.9875e-01, 2.9717e-04, 8.0675e-01]])
ReLU variance: 29.921340942382812
Sigmoid variance: 0.16309110820293427We noticed that SGD optimizer when used with ReLU activation function gives better and faster results than softmax and tanH. The softmax and tanH activations can reach eventully to lower loss and better performance but after taking too much time. Let’s see if we can get better results with a different optimizer. We will try with Adam optimizer, which is an adaptive learning rate optimization algorithm.
optimizer_11_adam = torch.optim.Adam(model_11.parameters(), lr=0.01)
losses_11_adam = train(model_11, X, Y, loss_fn, optimizer_11_adam, epochs=20)
# plot the loss curve
plt.plot(losses_11_adam)
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("Loss Curve")
plt.show()Epoch 1/20, Loss: 927.2076, Layer1 Grad Norm: 336.4995, Layer2 Grad Norm: 196.7563
Epoch 2/20, Loss: 913.3669, Layer1 Grad Norm: 325.1833, Layer2 Grad Norm: 180.3435
Epoch 3/20, Loss: 900.1819, Layer1 Grad Norm: 314.1475, Layer2 Grad Norm: 164.3676
Epoch 4/20, Loss: 887.6497, Layer1 Grad Norm: 303.4243, Layer2 Grad Norm: 148.8653
Epoch 5/20, Loss: 875.2734, Layer1 Grad Norm: 303.2852, Layer2 Grad Norm: 134.1216
Epoch 6/20, Loss: 861.5569, Layer1 Grad Norm: 370.3050, Layer2 Grad Norm: 120.3661
Epoch 7/20, Loss: 848.6948, Layer1 Grad Norm: 335.8414, Layer2 Grad Norm: 107.9534
Epoch 8/20, Loss: 836.5461, Layer1 Grad Norm: 332.4296, Layer2 Grad Norm: 97.0474
Epoch 9/20, Loss: 826.2305, Layer1 Grad Norm: 309.0845, Layer2 Grad Norm: 87.8428
Epoch 10/20, Loss: 816.1935, Layer1 Grad Norm: 307.6121, Layer2 Grad Norm: 80.5359
Epoch 11/20, Loss: 806.2573, Layer1 Grad Norm: 306.4871, Layer2 Grad Norm: 75.5798
Epoch 12/20, Loss: 796.4307, Layer1 Grad Norm: 305.7266, Layer2 Grad Norm: 73.3479
Epoch 13/20, Loss: 786.7112, Layer1 Grad Norm: 305.3355, Layer2 Grad Norm: 73.9706
Epoch 14/20, Loss: 777.0887, Layer1 Grad Norm: 305.3109, Layer2 Grad Norm: 77.2593
Epoch 15/20, Loss: 767.5464, Layer1 Grad Norm: 305.6438, Layer2 Grad Norm: 82.7801
Epoch 16/20, Loss: 758.8118, Layer1 Grad Norm: 280.3321, Layer2 Grad Norm: 90.0640
Epoch 17/20, Loss: 751.7449, Layer1 Grad Norm: 279.2271, Layer2 Grad Norm: 98.1964
Epoch 18/20, Loss: 744.8582, Layer1 Grad Norm: 283.0712, Layer2 Grad Norm: 106.4476
Epoch 19/20, Loss: 737.7630, Layer1 Grad Norm: 286.9029, Layer2 Grad Norm: 114.6683
Epoch 20/20, Loss: 730.4598, Layer1 Grad Norm: 290.7153, Layer2 Grad Norm: 122.8449
Target: tensor([10., 28., 40.])
Predictions: tensor([1.5349, 1.8247, 2.1242])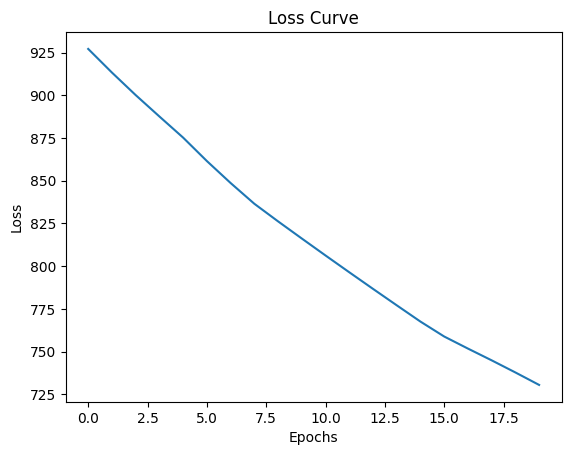
optimizer_sof_adam = torch.optim.Adam(model_sof.parameters(), lr=0.001)
losses_sof_adam = train(model_sof, X, Y, loss_fn, optimizer_sof_adam, epochs=20)
# plot the loss curve
plt.plot(losses_sof_adam)
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("Loss Curve")
plt.show()Epoch 1/20, Loss: 824.8789, Layer1 Grad Norm: 18.8638, Layer2 Grad Norm: 42.8995
Epoch 2/20, Loss: 824.7202, Layer1 Grad Norm: 19.3564, Layer2 Grad Norm: 42.7437
Epoch 3/20, Loss: 824.5600, Layer1 Grad Norm: 19.8609, Layer2 Grad Norm: 42.5869
Epoch 4/20, Loss: 824.3983, Layer1 Grad Norm: 20.3802, Layer2 Grad Norm: 42.4341
Epoch 5/20, Loss: 824.2351, Layer1 Grad Norm: 20.9173, Layer2 Grad Norm: 42.2894
Epoch 6/20, Loss: 824.0704, Layer1 Grad Norm: 21.4718, Layer2 Grad Norm: 42.1496
Epoch 7/20, Loss: 823.9039, Layer1 Grad Norm: 22.0432, Layer2 Grad Norm: 42.0113
Epoch 8/20, Loss: 823.7356, Layer1 Grad Norm: 22.6315, Layer2 Grad Norm: 41.8730
Epoch 9/20, Loss: 823.5654, Layer1 Grad Norm: 23.2370, Layer2 Grad Norm: 41.7341
Epoch 10/20, Loss: 823.3935, Layer1 Grad Norm: 23.8607, Layer2 Grad Norm: 41.5943
Epoch 11/20, Loss: 823.2194, Layer1 Grad Norm: 24.5032, Layer2 Grad Norm: 41.4539
Epoch 12/20, Loss: 823.0432, Layer1 Grad Norm: 25.1658, Layer2 Grad Norm: 41.3129
Epoch 13/20, Loss: 822.8646, Layer1 Grad Norm: 25.8497, Layer2 Grad Norm: 41.1718
Epoch 14/20, Loss: 822.6838, Layer1 Grad Norm: 26.5563, Layer2 Grad Norm: 41.0310
Epoch 15/20, Loss: 822.5004, Layer1 Grad Norm: 27.2872, Layer2 Grad Norm: 40.8910
Epoch 16/20, Loss: 822.3145, Layer1 Grad Norm: 28.0440, Layer2 Grad Norm: 40.7522
Epoch 17/20, Loss: 822.1257, Layer1 Grad Norm: 28.8286, Layer2 Grad Norm: 40.6149
Epoch 18/20, Loss: 821.9339, Layer1 Grad Norm: 29.6426, Layer2 Grad Norm: 40.4792
Epoch 19/20, Loss: 821.7391, Layer1 Grad Norm: 30.4873, Layer2 Grad Norm: 40.3449
Epoch 20/20, Loss: 821.5408, Layer1 Grad Norm: 31.3640, Layer2 Grad Norm: 40.2115
Target: tensor([10., 28., 40.])
Predictions: tensor([0.2144, 0.1306, 0.0981])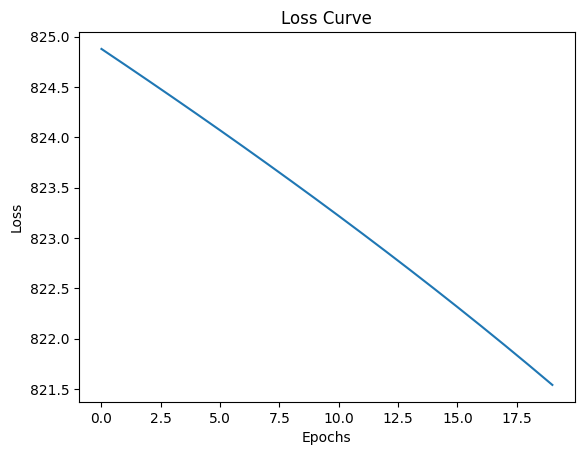
Next:::::: Invistigae why Adam optimer gives does not converge faster even with ReLU activation function.
Comments